Managing Video Datasets for Multimodal AI Training
Multimodal AI models need video data aligned with text, audio, and sensor inputs, but managing those datasets is far harder than managing images or text alone. This guide covers storage formats, metadata alignment strategies, versioning approaches, and tooling for teams building multimodal training pipelines at scale.

Why Video Datasets Break Standard ML Pipelines
Image classification pipelines deal in megabytes per sample. Video datasets deal in gigabytes. A single 4K training clip at 30fps generates roughly 500MB per minute of raw footage, and multimodal training multiplies that by adding synchronized audio tracks, text transcriptions, depth maps, and sensor logs.
The storage problem is only the start. Standard data loaders designed for image-text pairs choke on video because they assume random access to small files. Video files use temporal compression (each frame depends on previous frames), so reading frame 500 means decoding frames 1 through 499 first, unless your pipeline handles keyframe seeking correctly.
Multimodal video dataset management involves synchronizing temporal video frames with aligned text, audio, and sensor data for joint embedding training. Getting this alignment wrong means your model trains on mismatched pairs, which is worse than training on less data.
Three problems compound at scale:
- I/O bottlenecks: Sequential reads on local SSDs run 3-10x faster than random access. Network storage adds another order of magnitude of latency.
- Metadata overhead: Multimodal models need roughly 10x more storage metadata than unimodal models, because every frame needs cross-references to its aligned text, audio, and annotation data.
- Version drift: When you re-annotate a subset of clips or add new sensor modalities, tracking which version of which alignment file goes with which video cut becomes a full-time job.
Research teams consistently report that 80% of AI development time goes to data curation rather than model architecture. For video, that number feels conservative.
What to check before scaling video dataset management multimodal ai
The format you pick determines how fast your training loop runs, how much storage you burn, and how painful dataset updates become. Here are the main options, with tradeoffs.
WebDataset (TAR-Based Shards)
WebDataset packs samples into numbered TAR archives. Files with matching basenames (like sample001.mp4, sample001.json, sample001.wav) get grouped as a single training example. This format was built for sequential I/O, which makes it fast on both local drives and cloud object storage.
Strengths: No local caching needed for cloud storage. Scales from desktop experiments to petabyte datasets. Works natively with PyTorch DataLoader.
Limitations: Updating a single sample means rewriting the entire shard. Poor fit for datasets that change frequently.
Lance (Multimodal Lakehouse)
Lance stores video as encoded bytes alongside columnar metadata. You can scan metadata columns (filter by resolution, aesthetic score, or annotation quality) without fetching the video blobs. This "query first, fetch later" pattern avoids loading terabytes of video just to find the subset you need.
Strengths: Fast metadata filtering. Supports fine-grained data evolution without full rewrites. Native PyTorch and JAX data loading.
Limitations: Newer ecosystem with smaller community. Adds a dependency that simpler formats avoid.
VideoFolder (Directory Hierarchy)
The simplest approach: organize videos into train/label/video.mp4 directories. Labels come from folder names. Metadata lives in sidecar files. Hugging Face Datasets and torchvision both support this layout out of the box.
Strengths: Zero configuration. Human-readable structure. Easy to debug.
Limitations: Falls apart above a few thousand files. No built-in support for cross-modal alignment.
Comparison: Traditional vs. Multimodal Storage Requirements
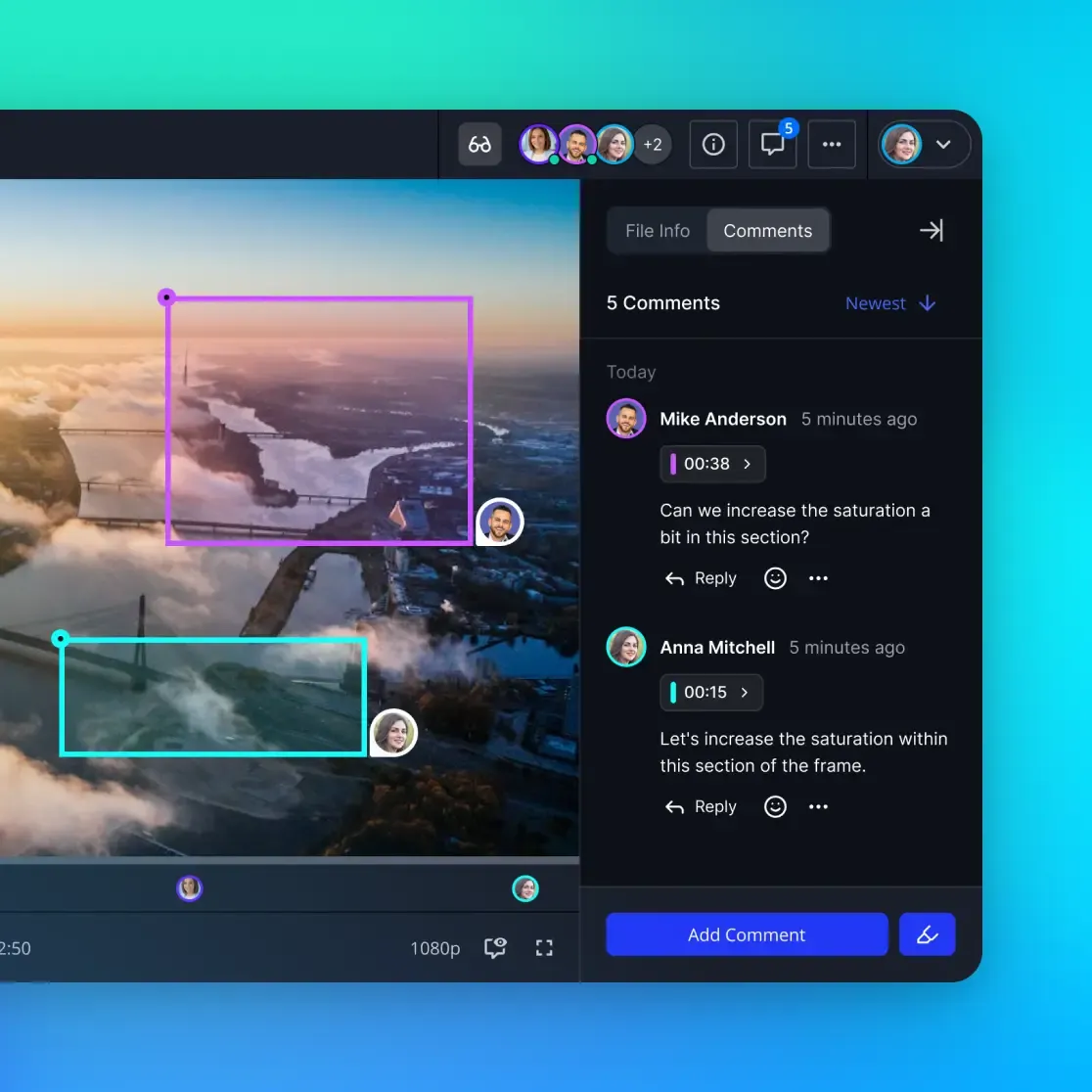
Aligning Video with Text, Audio, and Sensor Data
Alignment is the core technical challenge that separates video dataset management from generic file storage. Every frame in your training data needs precise temporal correspondence with its paired modalities.
Timestamp-Based Alignment
The most reliable approach anchors everything to presentation timestamps (PTS). PyTorch's torchcodec provides frame-level access with get_frame_at() returning both the decoded frame and its pts_seconds value. You can then map that timestamp to the corresponding audio segment, text caption, or sensor reading.
This works well when all modalities share a common clock. It breaks down when video was recorded at variable frame rates, or when audio and video were captured on separate devices with clock drift.
Annotation Layers
For training data that needs bounding boxes, segmentation masks, or semantic labels per frame, store annotations in a separate layer linked by frame index. The COCO RLE format (used by SAM and SAM2) compresses segmentation masks efficiently. Keep annotations in Parquet or JSON files alongside the video, not embedded in the video container.
Separating annotations from video data means you can re-annotate without touching the original footage. It also means multiple annotation passes (human labels, model-generated pseudo-labels, quality scores) can coexist as parallel layers.
Practical Alignment Workflow
- Extract keyframes from raw video using FFmpeg or torchcodec
- Generate timestamps for each extracted frame
- Align text using forced alignment tools (for speech) or manual caption timestamps
- Store cross-references in a metadata index that maps frame PTS to text spans, audio segments, and annotation files
- Validate alignment by spot-checking random samples before training
The metadata index is your single source of truth. If a frame's text caption is wrong, you fix the index. If you add depth maps as a new modality, you add a column to the index. The video files never change.


Organize your video training data in shared workspaces
Fastio gives your team versioned storage with granular permissions, chunked uploads for large video files, and an MCP server for agent-driven data pipelines. Start trial with 50GB storage, no credit card required. Built for video dataset management multimodal workflows.
Building an Efficient Data Loading Pipeline
A well-organized dataset is useless if your training loop spends more time waiting for data than computing gradients. Video decoding is CPU-intensive, and multimodal alignment adds overhead on top.
Multithreaded Decoding
PyTorch's video decoding backends support up to 32 threads for parallel frame extraction. For remote or network-attached storage, multithreaded decoding can deliver a 20x speedup over single-threaded reads. The video_reader backend (native C++) generally outperforms PyAV (Python FFmpeg bindings) for raw throughput.
Lazy Evaluation
Never decode an entire video upfront. Use range-based access like get_frames_in_range() to decode only the frames your training step needs. This is especially important for temporal sampling strategies where you might only need 16 frames from a 10-minute clip.
Checkpointing Data State
Long training runs on large video datasets can take days or weeks. PyTorch's StatefulDataLoader enables mid-epoch checkpointing, so you can resume exactly where you left off after a crash or preemption without replaying the entire dataset from the start.
Streaming from Cloud Storage
WebDataset supports streaming directly from cloud object stores without downloading the full dataset first. This is critical when your dataset is too large to fit on local disk. Combine streaming with prefetching (loading the next batch while the current batch trains) to hide network latency.
A typical pipeline looks like this:
Cloud Storage (S3/GCS) → WebDataset Shards → Streaming DataLoader
↓ ↓
Metadata Index → Frame Selection → Multithreaded Decode → GPU
The bottleneck usually shifts between network bandwidth, CPU decode throughput, and GPU utilization depending on your hardware. Profile before optimizing.

Versioning and Collaboration on Video Datasets
Video datasets evolve constantly. You add new clips, re-annotate existing ones, remove low-quality samples, and introduce new modalities. Without versioning, you lose the ability to reproduce results or understand why model performance changed between runs.
Version Metadata Separately from Video
Video files are large and rarely change. Metadata (annotations, alignments, quality scores) is small and changes frequently. Version them separately. Use DVC (Data Version Control) or a similar tool to track video file hashes, and use Git for metadata files. This way, a metadata update creates a small diff instead of duplicating terabytes of video.
Dataset Registries
Maintain a registry that records which combination of video files, metadata version, and processing parameters produced each training dataset. This is the difference between "we trained on the March dataset" and actually being able to reconstruct that exact dataset six months later.
Team Workflows
When multiple researchers work on the same dataset, conflicts happen. Two people annotate the same clip differently. Someone adds samples that overlap with the test set. A new preprocessing step changes frame extraction parameters.
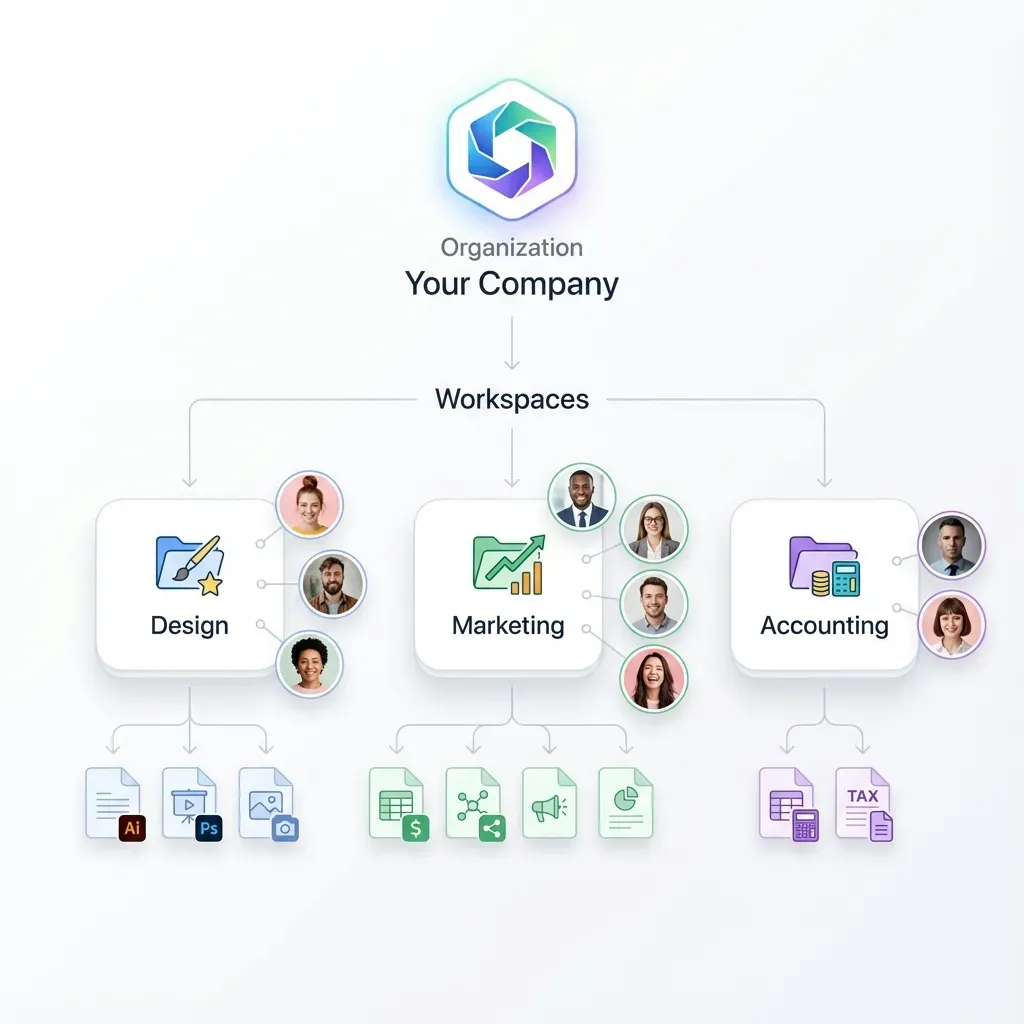
For teams managing large video datasets alongside other project files, a shared workspace with file versioning and granular permissions helps prevent these conflicts. Fastio workspaces provide file-level versioning with audit trails, so you can track who changed what and when. The granular permission model (down to individual files) lets you lock raw video files while keeping annotation layers editable.
For datasets that need to move between teams or from a data preparation pipeline to a training cluster, Fastio's chunked upload API handles large video files reliably, and the MCP server lets AI agents interact with workspace files programmatically. When your data preparation agent finishes processing a batch, it can upload results directly to a shared workspace where the training team picks them up.
Other options for team dataset management include Hugging Face Hub (good for public datasets with built-in viewers), DVC with remote storage backends like S3, and LakeFS for Git-like branching on object storage.
Scaling from Prototype to Production
Most teams start with a few hundred clips in a local directory and a CSV file for metadata. That works until it doesn't. Here's a practical progression for scaling your video dataset infrastructure.
Stage 1: Local Development (Under 100GB)
Use VideoFolder layout with sidecar JSON metadata. Load with Hugging Face Datasets or torchvision. Version with Git LFS or DVC. This is fast to set up and easy to debug.
Stage 2: Team Scale (100GB to 10TB)
Convert to WebDataset shards for faster I/O. Move storage to cloud object storage (S3, GCS). Add a metadata database (SQLite or Parquet files) for filtering and search. Implement a dataset registry for reproducibility.
At this stage, shared workspace tooling becomes important. You need access controls so the annotation team can't accidentally modify raw footage, and you need audit trails to track dataset changes across experiments. Fastio's workspace model fits here: teams share a workspace with role-based access, files are versioned automatically, and Intelligence Mode indexes uploaded data for search. The Business Trial includes 50GB of storage and 5 workspaces with no credit card required, which covers early-stage prototyping.
Stage 3: Production Scale (10TB+)
At this scale, you need distributed data loading, shard-level parallelism, and careful network topology planning. Lance or a custom data lakehouse becomes attractive for the metadata query layer. Video blobs stay in object storage, accessed through a streaming data loader.
Key decisions at production scale:
- Shard size: 256MB to 1GB per shard balances I/O efficiency with parallelism granularity
- Replication: Keep at least two copies of raw footage in different regions
- Garbage collection: Implement automated cleanup of orphaned annotations and expired dataset versions
- Monitoring: Track data loading throughput as a first-class training metric, not an afterthought
Common Pitfalls
- Storing decoded frames instead of compressed video: This multiplies storage costs by 10-50x. Decode on the fly.
- Mixing train and test data during augmentation: Keep strict dataset splits at the clip level, not the frame level. Frames from the same clip must stay in the same split.
- Ignoring codec differences: A dataset with mixed H.264 and H.265 clips will have inconsistent decode performance. Standardize during ingestion.
- Skipping data validation: Corrupted frames, misaligned timestamps, and truncated files waste GPU hours. Validate before training.
Frequently Asked Questions
What is multimodal video dataset management?
Multimodal video dataset management is the practice of organizing, storing, and versioning video files alongside their aligned text, audio, and sensor data for AI training. Unlike managing standalone video files, multimodal management requires maintaining precise temporal alignment between modalities, tracking annotation versions independently from raw footage, and supporting efficient random frame access for training data loaders.
How do you store video for multimodal AI?
The most common approaches are WebDataset (TAR-based shards for sequential I/O), Lance (columnar format with metadata queries), and VideoFolder (simple directory hierarchy). For production systems, store compressed video in cloud object storage with a separate metadata index for alignment information. Never store decoded frames, as this multiplies storage costs dramatically.
How much storage do multimodal video datasets require?
Multimodal video datasets typically require 3-5x the storage of the raw video alone, because you need to store aligned text transcriptions, audio tracks, annotation layers, metadata indices, and dataset version history. A 1TB raw video collection might need 3-5TB total when you include all aligned modalities and versioning overhead.
What tools are used for video dataset management in AI?
Common tools include PyTorch's torchvision and torchcodec for video decoding, Hugging Face Datasets for dataset loading and sharing, WebDataset for large-scale sharded storage, LanceDB for metadata-driven dataset management, and DVC for version control. For team collaboration and file management, platforms like Fastio provide versioned workspaces with API and MCP access for agent-driven pipelines.
How do you handle version control for large video datasets?
Version metadata separately from video files. Use DVC or Git LFS to track video file hashes (since the files themselves rarely change), and use standard Git for annotation files and metadata indices. Maintain a dataset registry that records exact combinations of video files, metadata versions, and processing parameters for each training run.
Related Resources

Organize your video training data in shared workspaces
Fastio gives your team versioned storage with granular permissions, chunked uploads for large video files, and an MCP server for agent-driven data pipelines. Start trial with 50GB storage, no credit card required. Built for video dataset management multimodal workflows.