Building AI-Native Video Storage Infrastructure
Guide to native video storage infrastructure: Traditional storage treats video as a playback stream. AI agents treat it as a queryable database. This guide covers the architecture shift required to support frame-level random access, metadata-heavy pipelines, and the I/O throughput that keeps GPU clusters productive instead of idle.

Why Traditional Video Storage Breaks Under AI Workloads
Video storage used to have one job: deliver bytes fast enough to prevent buffering. Whether a director reviewed raw footage or a consumer streamed a film, the access pattern was the same. Read from the beginning, move forward, stop at the end. Systems optimized for this sequential pattern worked well for decades.
AI agents don't watch video. A computer vision model might request frame 47, then frame 12,304, then frame 891, all within the same second. An object detection pipeline might run dozens of parallel passes on a single file to identify faces, track motion, extract text overlays, and classify scenes. A video generation model might read thousands of reference clips to produce a single output. These access patterns look nothing like playback.
This mismatch creates real problems. Most filesystems optimize for sequential writes (great for recording) but perform poorly under random-read loads. Cloud storage services that work fine for human file sharing become bottlenecks when an agent needs sub-millisecond frame retrieval across thousands of concurrent requests. The result is GPU starvation, where expensive compute hardware sits idle waiting for data that the storage layer can't deliver fast enough.
AI video pipelines require roughly 10x higher I/O than human editing workflows. A single 4K stream needs 25-50 Mbps for playback. But when an agent runs multi-pass analysis on that same file, the I/O requirement multiplies by the number of concurrent operations. Video processing workloads can demand 20+ GB/s of storage throughput, compared to 1-5 GB/s for language model training.
The core problem is that most infrastructure treats video as a black box, a single blob that's useless until fully downloaded and decoded. AI-native video storage treats it as structured, queryable data. Building for this difference is what separates functional AI video pipelines from ones that burn compute budget waiting on storage.
What to check before scaling ai-native video storage infrastructure
AI-native video storage is infrastructure specifically designed to support high-throughput, non-linear access by AI agents for frame extraction, analysis, and generation. Getting it right means building around three architectural pillars.
Pillar 1: High-Throughput Frame Random Access
AI agents access video frames the way databases serve rows: randomly, frequently, and in parallel. A vision model analyzing a surveillance feed might request frames from 50 different timestamps in a single batch. A training pipeline might sample millions of frames from thousands of videos, with no sequential relationship between requests.
This demands storage with strong random-read performance and near-zero seek time. According to industry benchmarks, real-time AI inference requires sub-millisecond latency to avoid stalling GPU pipelines. IOPS (Input/Output Operations Per Second) matter more than raw sequential throughput here. Purpose-built AI storage systems can deliver over 1,000,000 IOPS for random-read patterns, which is why they outperform systems optimized for moving large files sequentially.
The practical implementation typically involves NVMe storage for hot data, with a caching layer that pre-fetches frames based on predicted access patterns. Byte-range request support is essential, so agents can pull specific frames without downloading entire files.
Pillar 2: Metadata-First Architecture
In traditional workflows, metadata is an afterthought. A filename, a creation date, maybe a codec description. For AI video pipelines, metadata is the primary navigation system.
AI pipelines generate enormous volumes of structured metadata: technical data (bitrates, codecs, frame types, GOP boundaries), spatial annotations (bounding boxes, segmentation masks, pose estimates), temporal annotations (scene boundaries, shot changes, speaker diarization), and semantic labels (object tags, scene descriptions, sentiment scores). This metadata grows with every processing pass and can be as complex to store and query as the video itself.
Metadata overhead can account for 20% of total storage in AI workflows. If your system can't index and serve this metadata as quickly as it serves video frames, agents waste cycles searching instead of processing. A metadata-first architecture means:
- Storing metadata in high-performance key-value stores or columnar databases that scale independently of video data
- Indexing metadata at write time, not query time
- Supporting compound queries like "all frames containing a red vehicle between timestamps 00:14:00 and 00:22:00 with confidence above 0.85"
- Versioning metadata alongside the video it describes, so analysis results stay linked to their source material
Pillar 3: Semantic Data Accessibility
Legacy storage treats a .mp4 file as an opaque blob. AI-native storage treats it as a queryable sequence of addressable units.
The storage layer needs to understand video structure, or at least support the protocols agents use to navigate it. Instead of downloading a 50 GB file to find a 10-second clip, the storage should let an agent pull exactly the frames it needs through byte-range requests and frame-level index maps that record where every keyframe lives within the container.
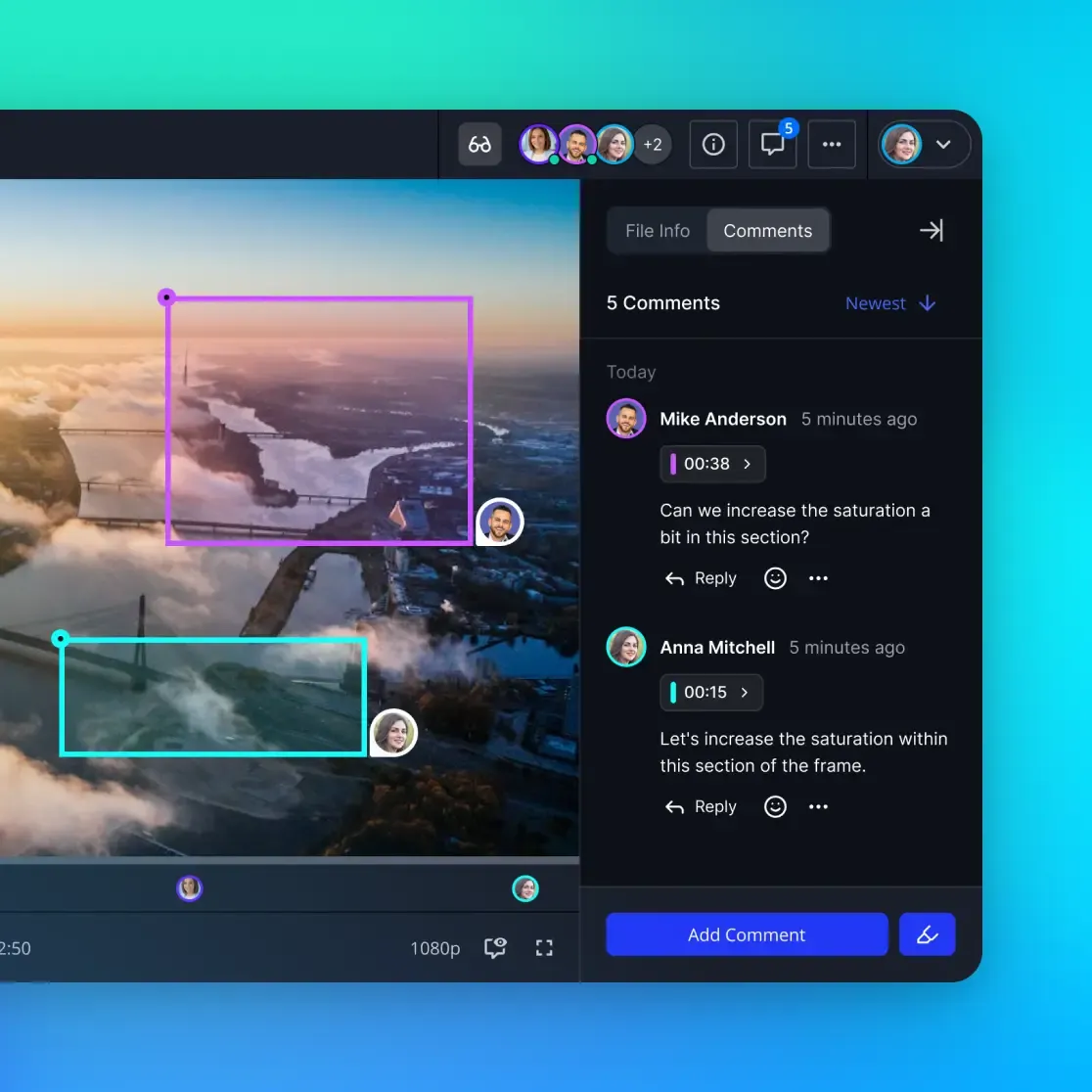
This pillar also covers content-based retrieval. When a production team asks "find all shots where the product is on screen," the storage layer should support vector similarity search across frame embeddings without requiring a separate retrieval system. Platforms like Fastio build this into their workspace intelligence layer, where uploaded video files are automatically indexed for semantic search and AI-powered chat with citations back to specific files and timestamps.


Stop building video storage from scratch
Fastio gives AI agents intelligent workspaces with automatic indexing, semantic search, and HLS video streaming. generous storage, no credit card, and your agents can start through the MCP server in minutes. Built for native video storage infrastructure workflows.
Storage Tiers and Hardware Architecture
Not all video data needs the same storage speed. A tiered architecture matches storage performance to access frequency, keeping costs manageable while maintaining throughput where it counts.
Hot Tier: Active Processing
Video files currently being analyzed, trained on, or generated belong on the fast storage available. NVMe SSDs are the standard here, offering the sub-millisecond latency and high IOPS that GPU-bound pipelines require. For large-scale deployments, NVMe-oF (NVMe over Fabrics) extends this performance across the network without adding significant latency.
NVIDIA's BlueField-4 architecture, announced at CES 2026, creates a purpose-built context memory tier that bridges high-speed GPU memory and scalable shared storage. The Inference Context Memory Storage Platform is designed specifically for agentic AI systems, delivering up to 5x improvement in tokens per second and power efficiency by enabling high-bandwidth context sharing across clusters. This represents the direction enterprise AI storage is heading: hardware designed from the ground up for agent workloads, not retrofitted from consumer storage.
The hot tier typically holds 5-15% of total video data but handles 80-90% of I/O operations.
Warm Tier: Recent and Reference Data Video files from recent projects, reference clips, and processed outputs that agents may need again soon belong on SATA SSDs or high-performance object storage. This tier trades some latency for lower cost per gigabyte. Access patterns here are less random and less frequent, so the performance tradeoff is acceptable.
The key design decision is the promotion/demotion policy between warm and hot tiers. Simple time-based policies (move to warm after 7 days of no access) work for some workflows, but AI pipelines benefit from smarter approaches. If a training run is scheduled to use a dataset next week, pre-promoting that data to the hot tier avoids a performance cliff when the job starts.
Cold Tier: Archive and Compliance
Raw footage, completed project archives, and regulatory retention copies go to high-density HDDs or deep cloud storage (S3 Glacier, Azure Cool Blob, GCS Coldline). Access is infrequent, retrieval can tolerate minutes to hours of delay, and cost efficiency is the priority.
For AI video operations, the cold tier has a nuance that traditional archives miss: metadata should stay warm even when video goes cold. An agent searching for "all footage of coastal environments shot in 2024" should be able to query metadata instantly, even if retrieving the actual video takes time. This means maintaining a metadata index that spans all tiers.
Practical Sizing
A mid-scale AI video operation processing 100 hours of 4K footage per week might allocate storage roughly as follows:
- Hot tier: 10-20 TB of NVMe (active processing queue, current training datasets)
- Warm tier: 50-100 TB of SSD-backed object storage (recent projects, reference libraries)
- Cold tier: 500+ TB of archival storage (raw footage, completed projects)
- Metadata store: 20-40 TB across all tiers (technical metadata, annotations, embeddings, indexes)
That metadata estimate lines up with the 20% overhead figure for AI workflows. It's a real cost center that traditional storage planning overlooks entirely.

Building the Pipeline from Ingestion to Agent Access
An AI-native video storage system isn't just a place to put files. It's a pipeline that transforms raw video into agent-accessible, queryable data. Here's how to structure that pipeline.
Stage 1: Ingestion and Transcoding
Raw video arrives in dozens of formats: ProRes from cameras, H.264 from screen recordings, HEVC from drones, VP9 from web captures. The ingestion layer needs to normalize these into formats optimized for AI access.
For frame extraction workloads, this often means transcoding to a format with frequent keyframes (every 1-2 seconds instead of the typical 5-10 second GOP). More keyframes means larger files but dramatically faster random frame access, since the decoder doesn't need to reconstruct frames from distant reference points. Some pipelines skip container formats entirely and store pre-extracted frames as individual images (JPEG or WebP) in object storage, trading storage efficiency for zero-decode-time access.
Chunked upload support matters here. Raw camera files routinely exceed 10 GB, and ingestion pipelines need to handle interrupted uploads gracefully. Fastio supports chunked uploads for large files, which is important for production environments where footage arrives continuously from multiple sources.
Stage 2: Metadata Extraction and Indexing
Once video is ingested, the system should immediately generate technical metadata: codec, resolution, framerate, bitrate profile, color space, audio tracks, and chapter markers. This happens at the storage layer, not in the application.
Semantic metadata extraction, including object detection, scene classification, speech-to-text, and face recognition, follows as a second pass. This is where GPU resources come in, running inference models against ingested video to produce structured annotations.
The indexing step is where metadata-first architecture pays off. Every annotation, embedding, and technical property gets indexed into a queryable store. Frame-level embeddings go into a vector database. Temporal annotations go into a time-series index. Technical metadata goes into a columnar store for fast filtering.
Fastio's Intelligence Mode automates part of this workflow. When enabled on a workspace, uploaded files are automatically indexed for semantic search and RAG-powered chat. This means agents can query video metadata through natural language without building a separate retrieval pipeline. The platform indexes uploaded content and supports citation-backed answers that reference specific files.
Stage 3: Access Layer and API Design
Agents interact with video storage through APIs, not file browsers. The access layer needs to support several access patterns simultaneously:
- Frame retrieval: Get frame N from video X, or get frames matching a temporal range
- Batch retrieval: Get 1,000 frames from 50 different videos in a single request
- Metadata query: Find all videos where object Y appears with confidence above threshold Z
- Streaming: Deliver a video segment as HLS or DASH for preview or quality review
- Write-back: Store analysis results, annotations, and derived assets alongside source video
For agent-driven workflows, MCP (Model Context Protocol) provides a standardized way for AI agents to interact with storage systems. Fastio's MCP server exposes workspace, storage, AI, and workflow operations through a consolidated toolset, letting agents manage files, query indexed content, and coordinate with human collaborators through a single protocol.
Handling Concurrency and Multi-Agent Coordination
AI video pipelines rarely involve a single agent working on a single file. Production systems run multiple agents in parallel, including object detectors, transcription engines, scene classifiers, quality analyzers, each accessing the same video files simultaneously. Without proper coordination, this creates conflicts, redundant work, and corrupted outputs.
File Locking for Write Safety
When multiple agents need to write annotations or derived data for the same video, file-level locking prevents conflicts. The pattern is straightforward: acquire a lock before writing, release it when done. But the implementation matters. Locks need to be distributed (not local to a single node), time-bounded (so a crashed agent doesn't hold a lock forever), and granular enough that locking one annotation file doesn't block access to the video itself.
Fastio supports file locks that agents can acquire and release through the API, which handles the distributed coordination. This is simpler than building your own locking system on top of a filesystem that wasn't designed for it.
Task Distribution and Deduplication A common failure mode in multi-agent video processing is duplicate work. Two agents independently decide to extract keyframes from the same video, or three agents each run speech-to-text on the same audio track. Task queues with deduplication logic prevent this waste.
The storage layer can help by maintaining a processing manifest, a record of which operations have been completed or are in progress for each video. Before starting work, an agent checks the manifest. If another agent is already handling the task, it moves on to the next item. This is more efficient than relying on external orchestration alone.
Ownership Transfer and Human Review
AI-processed video eventually needs human review. A quality control editor needs to verify that annotations are accurate. A producer needs to approve the final cut. A client needs to receive deliverables.
This handoff between agent processing and human review is a workflow gap that most storage systems ignore. Agent-oriented platforms like Fastio address it through ownership transfer, where an agent can build a complete workspace with processed video, annotations, and derived assets, then transfer it to a human collaborator who picks up where the agent left off. The agent can retain admin access for ongoing updates while the human takes ownership of the deliverable.
Branded shares add another dimension. An agent that processes client video can package the results into a branded share with the client's logo, password protection, and download controls, then deliver it directly without manual intervention.
Audit Trails for Reproducibility
When an AI pipeline produces unexpected results, you need to trace back through every processing step. Which agent ran which model on which frames? What version of the detection model was used? When were the annotations last updated?
Storage-level audit trails capture this automatically. Every file operation, access, modification, and deletion gets logged with the acting agent's identity and timestamp. This creates a complete provenance chain from raw footage to final output. Fastio's audit trails track file operations, AI activity, and membership changes across workspaces.
Choosing Your Storage Stack
No single product covers every requirement of an AI-native video storage architecture. Here's how the major options compare and where each fits.
Object Storage (S3, GCS, Azure Blob)
Object storage is the default choice for raw video and processed outputs. It scales to petabytes, costs relatively little per gigabyte, and supports byte-range requests for partial file access. Most AI frameworks have native S3 client libraries. The weakness is latency: object storage typically delivers 10-50ms for individual requests, which is acceptable for batch processing but too slow for real-time inference. IOPS are also limited compared to block storage.
Best for: Archive tier, batch training datasets, processed output storage.
Parallel File Systems (Lustre, GPFS, BeeGFS)
Parallel file systems are designed for high-throughput, multi-client access to shared data. They excel at the concurrent random-read patterns that AI video pipelines generate. Lustre installations can deliver hundreds of GB/s of aggregate throughput. The tradeoff is operational complexity: these systems require dedicated infrastructure, careful tuning, and experienced administrators.
Best for: Hot tier in on-premises or HPC environments with dedicated storage teams.
NVMe-oF and Composable Infrastructure
NVMe over
Fabrics extends local SSD performance across the network. Combined with composable infrastructure (disaggregated compute and storage that can be dynamically allocated), this approach delivers the lowest latency and highest IOPS available. NVIDIA's BlueField-4 STX architecture falls into this category, offering 4x higher energy efficiency than traditional CPU-based storage architectures for high-performance workloads.
Best for: Real-time inference, frame-level serving at scale, GPU-dense clusters.
Managed Workspace Platforms
For teams that don't want to build and maintain their own storage infrastructure, managed platforms handle the operational complexity. Fastio provides intelligent workspaces where uploaded video files are automatically indexed, searchable, and queryable through AI chat. The platform handles file versioning, access control, HLS video streaming for preview, and the collaboration layer between agents and humans.
The Business Trial includes 50 GB of storage, included credits, and 5 workspaces with no credit card required. For teams getting started with AI video processing, this removes the infrastructure setup time and lets you focus on the pipeline logic. Agents access the platform through the MCP server or REST API, and the built-in Intelligence Mode means you don't need a separate vector database for basic semantic search over video metadata.
Best for: Teams wanting agent-human collaboration, built-in RAG, and managed infrastructure without building from scratch.
Hybrid Approaches
Most production systems combine multiple tiers. A typical architecture might use NVMe for active processing, Fastio workspaces for collaboration and agent-human handoff, and S3 for long-term archival. The key is making the boundaries between tiers transparent to agents. An agent should query a unified API that handles tier routing automatically, not manage data placement manually.
When evaluating any storage option for AI video workloads, benchmark against your actual access patterns. Vendor throughput numbers usually reflect sequential reads on large files. Your workload probably involves small random reads across many files, which can perform 10x worse on the same hardware. Run your own benchmarks with realistic frame-extraction workloads before committing.
Frequently Asked Questions
What is AI-native storage?
AI-native storage is infrastructure designed from the ground up for machine-led access patterns rather than human file browsing. It prioritizes high IOPS for random reads, sub-millisecond latency, metadata-first indexing, and frame-level addressability. Instead of treating files as opaque blobs, AI-native storage makes content queryable and supports the concurrent, non-linear access patterns that AI agents and GPU pipelines require.
How much storage does an AI video pipeline need?
It depends on resolution, retention, and processing depth. A mid-scale operation processing 100 hours of 4K footage per week might need 10-20 TB of fast NVMe storage for active processing, 50-100 TB of SSD-backed storage for recent projects, and 500+ TB of archival storage. Add 20% on top for metadata overhead, which includes annotations, embeddings, frame indexes, and processing manifests that AI pipelines generate alongside the video data.
Why do AI video pipelines require more I/O than human editing?
Human editors access video sequentially, typically watching one or two streams at a time. AI agents access video randomly and in parallel, running multiple analysis passes simultaneously. An object detection model, a transcription engine, and a scene classifier might all hit the same file at once, each requesting different frames in unpredictable order. This creates roughly 10x higher I/O demand compared to a human editing the same footage.
What's the difference between IOPS and throughput for AI video storage?
Throughput measures how many bytes per second a storage system can deliver, which matters for streaming large sequential reads. IOPS measures how many individual read/write operations the system handles per second, which matters for the small, random frame-extraction requests that AI agents generate. For AI video workloads, high IOPS is usually more important than raw throughput because agents make many small requests rather than a few large ones.
Can cloud object storage work for AI video processing?
Cloud object storage (S3, GCS, Azure Blob) works well for batch processing, archival, and training dataset storage. However, individual request latency of 10-50ms makes it too slow for real-time inference or interactive agent workflows. Most production systems use object storage as a warm or cold tier, with faster NVMe or managed workspace storage handling the hot tier where active processing happens.
How does metadata-first architecture improve AI video workflows?
In traditional storage, metadata is a small afterthought. In AI video pipelines, metadata, including object annotations, scene classifications, frame embeddings, and processing history, can account for 20% of total storage. A metadata-first architecture indexes this data at write time, stores it in queryable databases separate from video data, and supports compound queries like 'find all frames with vehicles between timestamps X and Y.' This lets agents locate relevant content instantly instead of scanning entire video files.
Related Resources

Stop building video storage from scratch
Fastio gives AI agents intelligent workspaces with automatic indexing, semantic search, and HLS video streaming. generous storage, no credit card, and your agents can start through the MCP server in minutes. Built for native video storage infrastructure workflows.