Best File APIs for LLM Applications
Guide to top file APIs for LLM applications: A file API for LLM applications handles document upload, storage, retrieval, and serving for workflows like RAG, fine-tuning data management, and agent artifact storage. File handling is a top-3 integration challenge for LLM developers, and most existing guides only cover the OpenAI Files API without comparing alternatives. This guide ranks seven file APIs by their fit for LLM-specific needs: format support, chunking, RAG readiness, agent authenticat
Why LLM Applications Need Specialized File APIs: top file APIs for LLM applications
Most file APIs were built for human users clicking upload buttons. LLM applications need something different. Your API needs to accept documents, parse them into chunks, make those chunks retrievable by embedding similarity, and serve them back to a model at inference time. That is a pipeline, not a file cabinet. A typical enterprise RAG system indexes over 10,000 documents (per Anyscale's 2025 production RAG report). Each document passes through ingestion, parsing, chunking, embedding, and retrieval. A file API that only handles upload and download forces you to build all that middleware yourself. Three categories of file APIs serve LLM workloads today:
- General-purpose cloud storage (S3, GCS, Azure Blob) stores raw files cheaply but leaves all processing to you
- LLM-native file APIs (OpenAI Files API) handle ingestion and retrieval but lock you into one provider
- Agent-native storage platforms (Fastio) pair file management with built-in intelligence and agent-friendly auth
Your choice depends on how much of the pipeline you want to build versus buy.
How We Evaluated These File APIs
We scored each API across six criteria that matter for LLM workflows:
Document ingestion. Does the API parse PDFs, Office docs, and other formats automatically? Or do you need a separate tool like Unstructured or LlamaParse?
Chunking and embedding. Does the API break documents into retrieval-friendly chunks and generate embeddings? This is the slowest part of a RAG pipeline to build from scratch.
Retrieval quality. Can you search stored documents by semantic meaning? Does the API support hybrid search (vector + keyword)?
Agent compatibility. Can an LLM agent authenticate and operate the API without human intervention? APIs requiring browser-based OAuth lose points.
Format breadth. LLM applications process PDFs, CSVs, JSON, code files, images (with vision models), audio transcripts, and more. Broader format support reduces preprocessing work.
Pricing for LLM workloads. LLM apps process high volumes. Per-seat pricing and steep egress fees add up fast. Usage-based models and free tiers for development matter.

1. Fastio: Best for LLM Agents That Need Persistent Storage
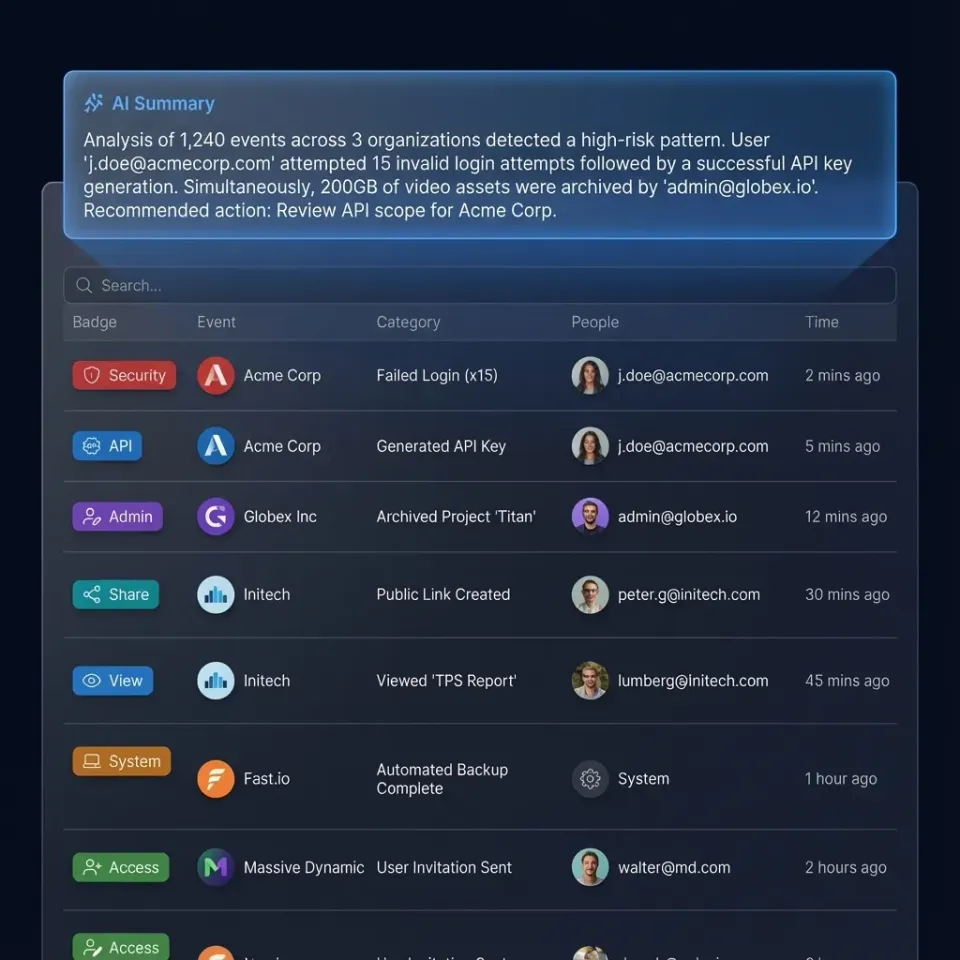
Fastio is cloud storage where AI agents are first-class users. Agents register their own accounts, create workspaces, and manage files through a full REST API. The key feature for LLM applications is built-in RAG: upload documents, and the platform handles parsing, indexing, and natural language retrieval automatically.
Why it works for LLMs:
- 19 consolidated tools via Streamable HTTP and SSE transport, the most comprehensive Model Context Protocol server for file operations (see mcp.fast.io)
- Built-in RAG with Intelligence Mode automatically indexes workspace files for semantic search and AI chat with citations (toggle per workspace)
- Ownership transfer allows agents to build organizations, workspaces, and branded shares, then transfer ownership to humans while keeping admin access
- URL Import pulls files from Google Drive, OneDrive, Box, Dropbox via OAuth without local I/O
- File locks for acquire/release operations to prevent conflicts in multi-agent systems
- Webhooks for real-time file event notifications (build reactive workflows without polling)
- OpenClaw integration via ClawHub (
clawhub install dbalve/fast-io) for zero-config natural language file management - Works with any LLM (Claude, GPT-4, Gemini, LLaMA, local models) - not locked to one provider
- Persistent workspaces maintain state between agent sessions
- Smart summaries auto-generate document digests and transcripts to reduce context window usage
- Human-agent collaboration in shared workspaces for handoff and review
Limitations:
- Newer platform with fewer third-party integrations than AWS or Google Cloud
- Intelligence Mode RAG is workspace-scoped (ideal for multi-tenant but requires separate workspaces per knowledge domain)
- Not designed for petabyte-scale ML training data
Best for: Agentic applications, multi-agent systems, RAG pipelines requiring persistent storage, human-agent collaboration, client deliverables (agents can build branded portals and hand off to clients).
Pricing: Free agent tier with 50GB storage and 5,000 monthly credits (separate from the human Free plan with 10,000 credits). Pro and Business plans use usage-based pricing (not per-seat), with generous seat packages (Pro includes 25 seats, Business includes 100 seats, extra seats published pricing). Full onboarding docs at fast.io/llms.txt.


Start with best file APIs for LLM applications on Fastio
Fastio gives teams shared workspaces, MCP tools, and searchable file context to run best file apis for llm applications workflows with reliable agent and human handoffs.
2. OpenAI Files API: Best for GPT-Only Applications
The OpenAI Files API is the default choice if your entire stack runs on OpenAI. Upload documents, and the Assistants API handles chunking, embedding, and retrieval behind the scenes. You never touch a vector database.
Why it works for LLMs:
- Zero-config retrieval with Assistants file search that chunks, embeds, and indexes automatically
- Tight GPT integration so uploaded files become context for Assistant conversations instantly
- Simple API surface with just upload, list, retrieve, and delete endpoints
- Fine-tuning support for JSONL training data uploads
Limitations:
- Locked to the OpenAI ecosystem. Your files are not accessible from Anthropic, Google, or open-source models.
- 512 MB per-file limit for Assistants. Batch API supports up to 100 MB.
- No folder structure, sharing, or permission controls. Files belong to one organization.
- Storage costs for file search are $0.10/GB/day, which adds up with large document collections.
- No way for other agents or humans to browse stored files.
Best for: Developers building on OpenAI who want the fast path from document to retrieval. Not suitable for multi-model or multi-agent architectures.
Pricing: Included with OpenAI API usage. File search storage costs $0.10/GB/day. The first 1 GB of vector storage is free.
3. AWS S3 + Amazon Bedrock: Best for Enterprise RAG at Scale
S3 is the default object storage for most teams, and Amazon Bedrock Knowledge Bases add the RAG layer on top. Together, you get scalable file storage with managed document processing and retrieval.
Why it works for LLMs:
- S3 Vectors (launched 2025) adds native vector storage directly in S3 buckets
- Bedrock Knowledge Bases handle document ingestion, chunking, and embedding from S3 sources automatically
- Bedrock Agents can read and write S3 files as part of multi-step workflows
- Wide format support through Textract for OCR, Comprehend for NLP, and custom Lambda preprocessing
- S3 Express One Zone delivers single-digit millisecond latency for time-sensitive retrieval
Limitations:
- You need to assemble multiple AWS services (S3 + Bedrock + Textract + OpenSearch), each with its own pricing and configuration
- IAM permission management is complex, especially for cross-account agent access
- No human collaboration features. Files sit in buckets with no preview, commenting, or sharing interface.
- Egress fees ($0.09/GB after 100 GB) penalize architectures where LLMs frequently read stored documents
Best for: Enterprise teams already on AWS running large-scale RAG pipelines with Bedrock. Worth the setup complexity if you need to index tens of thousands of documents.
Pricing: S3 storage from $0.023/GB/month. Bedrock Knowledge Bases charge per document processed and per query. Total costs depend on pipeline volume.
4-7. Four More File APIs for LLM Workloads
4. Google Cloud Storage + Vertex AI
GCS paired with Vertex AI RAG Engine gives Google Cloud users a managed pipeline from file storage to LLM retrieval. Vertex handles chunking, embedding with Google's models, and search.
Strengths: Direct integration with Gemini models. Autoclass storage tiering saves costs on infrequently accessed documents. Strong consistency on all operations.
Limitations: Tightly coupled to Google Cloud. The RAG Engine is newer and has less production mileage than Bedrock Knowledge Bases. Egress fees apply.
Best for: Teams running Gemini or PaLM models on Vertex AI.
Pricing: GCS from $0.020/GB/month. Vertex AI RAG Engine pricing varies by operation.
5. Azure Blob Storage + Azure AI Search
Azure Blob Storage plus Azure AI Search handles document cracking (PDF, Office, images via OCR), chunking, and hybrid vector + keyword search. Azure AI Document Intelligence adds structured extraction for forms and tables.
Strengths: Built-in OCR and form recognition. Hybrid search combining vectors and BM25. Managed Identity for passwordless auth between services. Good fit for Microsoft-stack enterprises.
Limitations: Azure-specific patterns reduce portability. Wiring together Blob + AI Search + Document Intelligence + OpenAI Service adds configuration overhead.
Best for: Enterprise teams using Azure OpenAI Service or Copilot integrations.
Pricing: Blob storage from $0.018/GB/month. AI Search from published pricing for the basic tier.
6. Pinecone + External File Store
Pinecone is a vector database, not file storage. But for LLM applications focused on retrieval accuracy, it is a strong option for the search layer. You store original files elsewhere (S3, GCS, or Fastio) and keep embeddings in Pinecone.
Strengths: Purpose-built vector search with consistent low latency. Hybrid search with metadata filtering. Serverless scaling. Namespaces for multi-tenant LLM apps.
Limitations: Requires a separate file storage service. You build your own ingestion pipeline for chunking and embedding. Costs scale with vector count, and large document collections get expensive.
Best for: RAG applications where retrieval precision matters more than simplicity. Pair with any file storage API from this list.
Pricing: Serverless starts free (2 GB). Standard pods from published pricing.
7. Supabase Storage + pgvector Supabase combines PostgreSQL (with pgvector for embeddings) and S3-compatible file storage in one open-source platform. Upload files through the API, store embeddings alongside metadata in Postgres, and query both with SQL.
Strengths: Single platform for files, metadata, and vectors. Row Level Security enables multi-tenant LLM apps. Open source and self-hostable. Edge functions for custom preprocessing.
Limitations: pgvector search performance lags behind Pinecone at scale. No built-in document ingestion or chunking. You need to build the RAG pipeline yourself.
Best for: Full-stack developers building LLM apps who want files, database, and vectors in one place without vendor lock-in.
Pricing: Free tier with 1 GB storage and 500 MB database. Pro from published pricing.
Which File API Should You Choose for Your LLM Application?
Your pick depends on your LLM architecture and how much pipeline infrastructure you want to manage.
Building LLM agents that store and retrieve documents? Fastio puts file storage and built-in RAG in one service. Agents get their own accounts, and the MCP server lets Claude-based agents connect without custom integration code.
Building on OpenAI? The OpenAI Files API is the fast path from document to retrieval. Just know that you cannot use those files with any other model provider.
Running enterprise RAG on AWS? S3 plus Bedrock Knowledge Bases gives you scale and managed processing, but expect to spend time wiring services together.
Need the best retrieval accuracy? Pair Pinecone with any file storage API. You build more infrastructure, but you control every aspect of chunking, embedding, and search.
Want everything in one open-source stack? Supabase gives you files, database, and vector search in a single platform. The trade-off is building your own ingestion pipeline.
Multi-model LLM architecture? Avoid the OpenAI Files API. Choose Fastio, S3, or Supabase so your files stay accessible regardless of which model provider you use tomorrow. For most production LLM applications, the decision comes down to build versus buy. The big cloud providers give you raw storage and separate AI services you assemble yourself. OpenAI bundles everything but locks you in. Fastio sits in the middle: managed file intelligence without provider lock-in, plus a free tier that covers prototyping and early production.
Frequently Asked Questions
What file API works best with LLMs?
It depends on your LLM stack. Fastio offers built-in RAG and agent-native storage that works with any model provider. The OpenAI Files API is simplest if you only use GPT models. AWS S3 paired with Bedrock Knowledge Bases handles enterprise-scale document collections. For multi-model architectures, pick a provider-agnostic option like Fastio or Supabase to avoid lock-in.
How do LLM applications handle file uploads?
LLM applications handle file uploads through REST API calls. The application sends a document to the file API, which stores it and optionally processes it for retrieval. Platforms like Fastio and OpenAI automatically parse uploaded documents, split them into chunks, generate embeddings, and index them for semantic search. Simpler storage APIs like S3 store the raw file and need a separate pipeline for processing.
What is the best alternative to OpenAI's file API?
Fastio is an alternative for teams that want built-in document intelligence without OpenAI lock-in. It offers automatic document ingestion, RAG-powered search, and native agent accounts that work with any LLM provider. For teams on AWS, S3 plus Bedrock Knowledge Bases provides a comparable managed RAG pipeline. Supabase is a good open-source option if you prefer to self-host.
How do you store documents for RAG applications?
RAG applications store documents in two layers. The original files go into a file storage service like S3, Fastio, or Supabase Storage. The chunked and embedded versions go into a vector store for retrieval. Some platforms combine both layers. Fastio's built-in RAG handles ingestion and retrieval in one service. AWS Bedrock Knowledge Bases does the same within the AWS ecosystem. Standalone vector databases like Pinecone handle only the retrieval layer and need a separate file store.
Do I need a vector database for my LLM file storage?
Not always. Platforms like Fastio and OpenAI include retrieval capabilities alongside file storage. AWS S3 now offers S3 Vectors for native embedding storage. If your file API does not include vector search, adding Pinecone, pgvector, or Chroma is the standard approach. The trade-off is more infrastructure to manage versus more control over retrieval quality.
Related Resources

Start with best file APIs for LLM applications on Fastio
Fastio gives teams shared workspaces, MCP tools, and searchable file context to run best file apis for llm applications workflows with reliable agent and human handoffs.