How to Set Up AI Agent File Sync Across Sessions
AI agent file sync maintains consistent file state across agent runs and workspaces. Without synchronization, agents lose intermediate files and progress whenever they restart between sessions. Fastio provides persistent cloud workspaces where agents can upload, update, and retrieve files using MCP tools or REST APIs. This architecture supports complex data processing pipelines, multi-step reasoning, and multi-agent collaboration.

What Is AI Agent File Sync?
AI agent file sync maintains consistent file state across agent runs and workspaces. Agents regularly create files like processed data, logs, trained models, or analytical reports. Without a persistent synchronization layer, those files disappear the moment the session ends. When that happens, agents are forced to start their tasks completely from scratch.
According to industry benchmarks, agents require persistent sync for 80% of production workflows. The synchronization process works straightforwardly. An agent writes its output to stable storage during an active run. In the next run, it reads those exact files to resume its work. This mechanism provides memory that goes beyond simple chat history or temporary RAM. Files remain available until explicitly deleted, surviving agent restarts, language model switches, or underlying infrastructure changes.
Fastio workspaces provide this storage layer. Agents access these workspaces through multiple MCP tools or standard REST APIs. Files stay accessible even when the agent restarts, switches between Claude and GPT-multiple, or migrates to different cloud infrastructure. Fastio also includes built-in RAG capabilities through Intelligence Mode.
The technical implementation relies on three core operations. First, checkpoint writing involves agents serializing their current state to JSON or binary files at defined intervals. Second, state recovery happens on startup when agents read these checkpoint files to restore their previous position. Third, atomic updates using file locks prevent data corruption when multiple agents attempt to work on shared files simultaneously.
Consider a research agent tasked with collecting academic papers from arXiv. Run multiple downloads multiple PDFs and saves the metadata to a structured JSON file. Run multiple loads that metadata, skips the already-downloaded papers, and continues processing from where it stopped. Without synchronization, every single run starts over, which wastes bandwidth, API calls, and time.
For engineering teams building complex agent systems, this persistence layer transforms unreliable prototypes into production-ready workflows. Differences show in lower token costs, faster processing, and better reliability.
Helpful references: Fastio Workspaces, Fastio Collaboration, and Fastio AI.

Why AI Agents Need Persistent File Sync
Agent workflows frequently span multiple steps over extended periods of time. A single session rarely covers an entire complex business process. File synchronization allows agents to save their progress securely and continue their work later.
Take a data analysis agent processing large monthly sales reports. The workflow breaks down into distinct phases. During the first run, the agent fetches sales data from an external API and saves a multiple CSV file. During the second run, it loads that CSV, removes duplicates, calculates key performance indicators, and saves the resulting analysis as a JSON file. Finally, in the third run, it loads the analysis to generate a PDF document with charts and uploads the final report.
Without proper synchronization, the second run would have to re-download the raw data, wasting hundreds of tokens. The third run would need to re-analyze everything from scratch. This redundant processing creates a massive waste of resources and slows down the entire pipeline.
Production agents handle this exact pattern daily for ETL pipelines, model training checkpoints, and automated report generation. Synchronization turns unreliable chat sessions into dependable production pipelines.
Several real-world use cases benefit from persistent synchronization. ETL pipelines process data in stages, often running overnight or across different time zones. Each stage produces specific artifacts that the subsequent stage requires to function. Training loops for machine learning models save checkpoints every few epochs. If the training process interrupts unexpectedly, resuming from the last valid checkpoint avoids starting the entire process over.
Multi-agent workflows introduce another layer of complexity that requires synchronization. One specialized agent might scrape data from the web while a different agent analyzes it. They coordinate their activities through shared files stored in Fastio workspaces. Agents can process file batches overnight, share refined datasets with other specialized agents, and eventually hand off the finished work to human team members. Persistent files drastically cut down on repeat work and systemic errors.



Start AI Agent File Sync Today
Get 50GB of free persistent storage, 5 dedicated workspaces, and full access to 19 consolidated tools. No credit card required. Build reliable agents that pick up exactly where they left off.
Common Problems Without File Sync
Temporary storage introduces severe reliability issues for autonomous agent systems. Understanding these failure modes shows why persistent synchronization matters for production environments.
Many common APIs delete files after a set time period or the moment an assistant thread ends. Development teams get surprised when key data vanishes without warning. Agents lose access to their knowledge bases instantly. Local files stored in ephemeral containers or serverless functions disappear the second the instance restarts. Developers often spend days trying to figure out why their agents suddenly "forgot" important context. Fastio storage survives these infrastructure restarts completely intact.
Restart loops waste massive amounts of computational resources. Without state persistence, every single run starts from the absolute beginning. Web scrapers re-download identical pages. Processing pipelines re-check the exact same database records. These costs add up quickly in API tokens and compute time. A ten-step data pipeline that runs daily wastes nine steps worth of expensive work every morning because nothing persisted overnight.
Multi-agent setups struggle immensely to coordinate without shared state. Two agents working on one project will frequently overwrite each other's outputs. One agent saves a results file, and another agent immediately replaces it. Without file locks, this causes silent data corruption. The second agent might read partial data, produce entirely wrong results, and nobody notices the error until customers complain. Explicit file locks solve this exact problem by ensuring only one agent can modify a specific file at any given time.
Humans cannot easily monitor agent progress without persistent files. Folders full of intermediate results vanish between active sessions. There is no reliable way to check intermediate work or audit what happened during a complex run. When something breaks in production, debugging becomes nearly impossible because the forensic evidence disappeared. Fastio keeps files safely stored until you explicitly delete them, providing a clear audit trail of what the agent did and when.
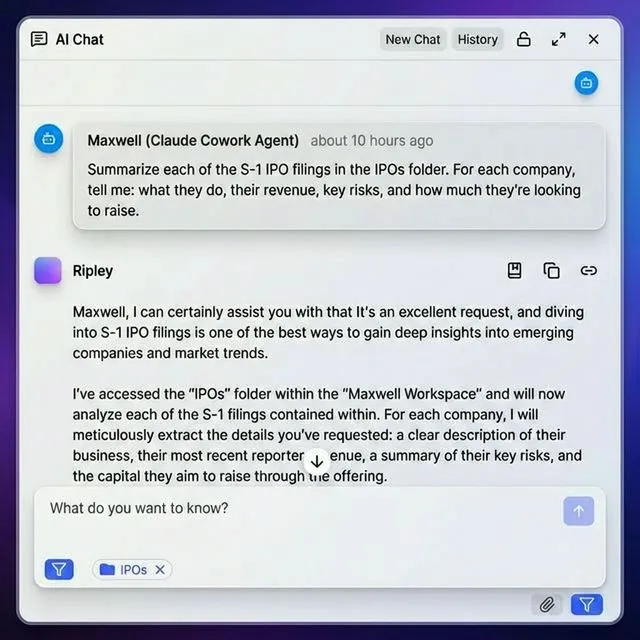
Fastio vs Other Agent File Sync Options
Evaluating the available options for AI agent file synchronization reveals significant differences in capability and engineering overhead. Here is how Fastio compares to the most common alternatives developers consider.
AWS S3 provides highly reliable cloud storage but requires significant upfront setup and ongoing maintenance. You must configure complex bucket policies, manage secure access keys, handle SDK integration, and build your own error retry logic. While S3 works well for large-scale enterprise production systems, it adds substantial engineering overhead that slows down rapid agent development.
The OpenAI Files API is strictly limited to file uploads specifically for fine-tuning models or basic attachments. It does not support the checkpoint-based workflows that autonomous agents actually need. Files disappear after they are used, making the service entirely unsuitable for maintaining persistent agent state across multiple sessions.
Relying on the local filesystem works fine during initial local development but fails predictably in production environments. Serverless functions use ephemeral storage that wipes clean between invocations. Docker containers lose all local data when they restart or crash. Kubernetes pods frequently reschedule to entirely new nodes. You cannot rely on local temporary storage for serious production agents.
Fastio eliminates these infrastructure hassles while providing agent-specific features right out of the box. The platform includes native MCP integration, automatic RAG indexing through Intelligence Mode, explicit file locks for concurrency, and webhooks for event-driven architectures. The Business Trial provides 50GB of persistent storage, supporting files up to 1GB in size, which covers the vast majority of agent use cases without requiring a credit card.
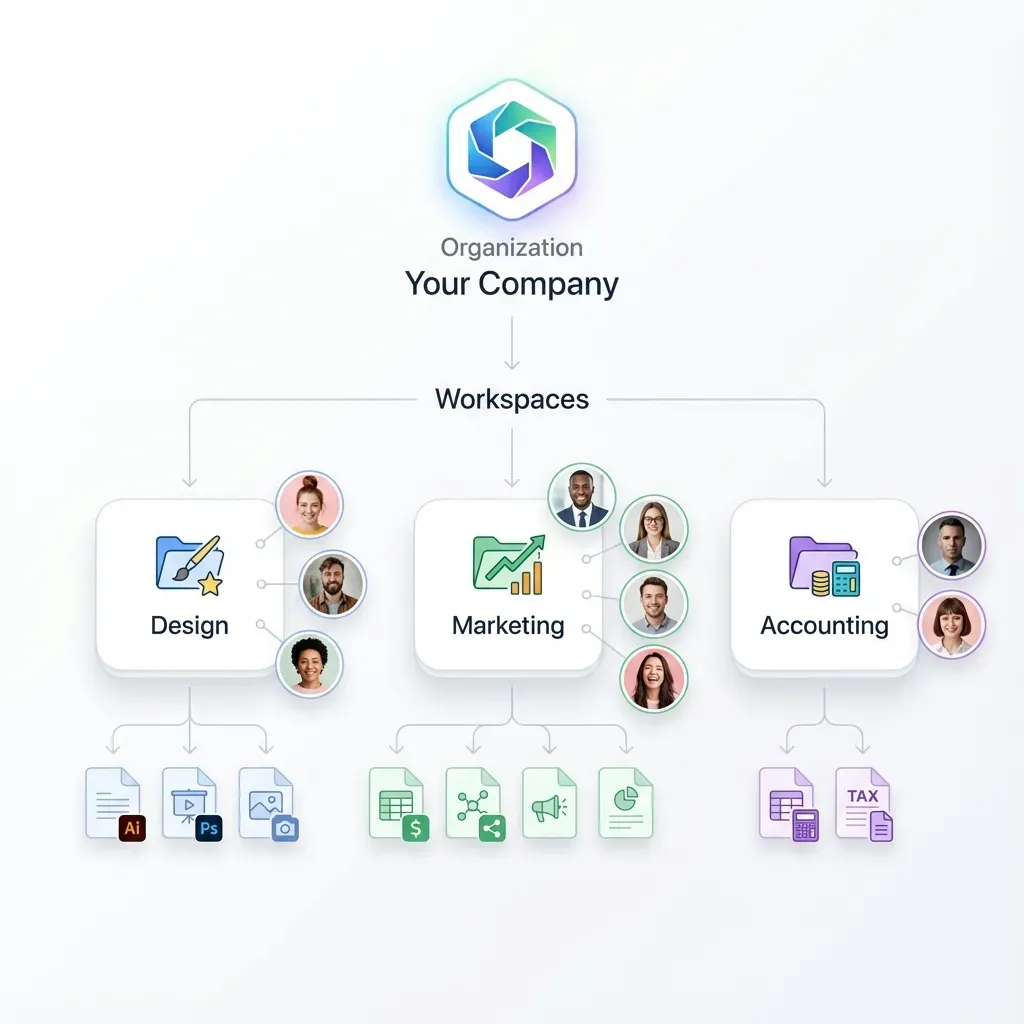
MCP vs REST API: Choosing Your Integration Approach
Fastio supports two distinct integration paths for file synchronization. Both the Model Context Protocol (MCP) and the traditional REST API provide full access to the same storage capabilities, but they suit completely different agent architectures.
The MCP integration works well with Claude, the OpenAI Agents SDK, and other protocol-compatible frameworks. The Fastio MCP server exposes essential file operations directly as tools. Your agent can call upload, download, list, delete, lock, and unlock tools the exact same way it calls the underlying language model. This approach keeps your application code remarkably clean and works flawlessly with any LLM that supports standard tool calling.
The REST API approach suits agents built with custom HTTP clients, LangChain, or specialized frameworks that lack native MCP support. The API follows strict, standard REST patterns. You use GET requests for reads, POST requests for creates, PUT requests for updates, and DELETE requests for removals. This method gives developers highly granular control over network requests but requires writing more boilerplate code to handle authentication and error states.
For the vast majority of agent projects, MCP provides a much faster development experience. The tools are ready to use immediately. For complex production systems needing fine-grained network control, the REST API offers maximum flexibility. You can easily mix both approaches within the exact same workspace depending on what specific task the agent is performing.
The Fastio MCP server runs over Streamable HTTP or Server-Sent Events (SSE), maintaining reliable session state through Durable Objects. This architecture handles network reconnections. If an agent disconnects unexpectedly mid-operation, it can resume its work without data loss or corruption.

Setting Up AI Agent File Sync: Complete Walkthrough
Setting up persistent file synchronization with Fastio requires only a few steps. You can have a production-ready storage layer running in minutes.
First, sign up for an agent account at Fastio. The free tier includes 50GB of storage, 5 distinct workspaces, and included credits. You do not need a credit card to start building.
Next, create a dedicated workspace using the MCP workspace creation tool or the REST API. Name the workspace , such as "agent-project-sync", so you can easily identify its purpose later. This workspace serves as the persistent home for all the files your agent generates and consumes.
During the agent's first run, configure it to upload explicit checkpoints. Use the file upload tool to save the current processing stage, the last item processed, and any relevant metadata to a JSON file. This simple checkpoint file is the key to resuming work later.
When the agent needs to resume work, it first lists the available files in the workspace. It reads the checkpoint file, parses the JSON data, and uses that information to continue its processing from the correct location.
For multi-agent systems, always implement file locks. Before an agent modifies a shared file, it must acquire the lock for that specific path. Once the work completes, the agent releases the lock. This pattern prevents the silent data corruption that ruins complex agent workflows.
Finally, test your failure scenarios intentionally. Forcefully kill the agent process right in the middle of an operation. Restart the agent and verify that the files are still safely stored in the workspace and that the agent correctly resumes from its last valid checkpoint.
Troubleshooting Common File Sync Issues
File synchronization setups occasionally encounter friction during initial development. Here is how to diagnose and fix the most common problems developers face.
When agents report that a file is not found upon resuming, the cause is usually straightforward. The agent might be looking in the wrong workspace ID. Always hardcode or explicitly pass the correct workspace ID in the agent's initial prompt. Sometimes, the initial upload failed silently because the code did not check the response status. Always add proper logging to verify that uploads succeed. Also, ensure the agent uses absolute paths starting from the root directory to avoid confusing relative path errors.
Lock contention happens frequently in active multi-agent environments. If one agent cannot acquire a lock, it will fail. The reliable fix is to implement an exponential backoff retry mechanism. If the lock is busy, the agent should wait a short time and try again, increasing the wait time with each failed attempt. If it still fails after several tries, it should fall back to creating a uniquely named temporary file to avoid blocking entirely.
Uploads failing mid-run usually point to rate limits or token exhaustion. For large files exceeding multiple, you must use the chunked upload API instead of trying to send the entire file at once. Always monitor your available credits. The system charges multiple credits per gigabyte of storage and multiple credits per gigabyte of bandwidth. If you process large amounts of data, queue operations across multiple runs using webhooks to spread the load.
Permission errors indicating access denied almost always relate to token scopes. Regenerate your access token and verify it includes the necessary scopes for reading, writing, locking, and workspace management. You can review the detailed audit logs to see exactly what identity attempted the access and why the system rejected it.
Use the MCP documentation and the built-in audit logs for all debugging sessions. The logs show the exact API calls, detailed error messages, and precise timestamps, making it much easier to track down elusive bugs.
Best Practices for Agent File Sync
Following established best practices ensures your agent file handling remains reliable as your systems scale in complexity.
Adopt consistent naming conventions using dates or UUIDs. Paths like /runs/multiple-multiple-multiple/checkpoint.json prevent overlaps and make files easy to locate. This approach mimics how Git organizes folders and makes it simple to understand the exact timeline of agent activity and clean up old runs without risking accidental deletion of active work.
Always version your important output files. Instead of overwriting report.json, save files as report-v1.json and report-v2.json. Keeping this history makes it easy to compare changes. When agents regenerate their outputs, having versioned files lets you compare the precise results, roll back to previous versions if something breaks, and understand the evolution of the agent's outputs over time.
Organize folders strictly by run or project. Grouping related files simplifies cleanup operations and keeps workspaces logical. This helps a lot when debugging difficult issues. You can easily isolate problem areas without sorting through hundreds of unrelated files.
Use webhooks for triggering subsequent actions. When an agent finishes uploading a final report, the webhook can automatically trigger notifications or start the next agent in the sequence. This creates a reactive system and eliminates the need for continuous polling.
Rely on audit logs to track all file views, downloads, and modifications. This visibility helps with compliance and is useful for debugging. Every file operation gets recorded with a timestamp, the acting user, and the specific action taken. When something goes wrong in production, audit logs help you reconstruct what happened step by step.
Test failure scenarios intentionally and frequently. Kill agents mid-operation, simulate severe network failures, and test exactly what happens when storage space runs low. The more failure modes you test during development, the more reliable and resilient your agent systems become in production.
Security Considerations for Agent File Storage
When autonomous agents handle files, security requires attention. Several key factors demand configuration to protect your data.
Access tokens should use minimal scopes. Agents only need read, write, and lock permissions for their assigned workspace. Avoid giving agents broader access than necessary for their tasks. If an agent's token gets compromised by a malicious prompt injection, limited tokens reduce the blast radius of the attack.
Workspace isolation keeps different agents separate. Each agent or specialized agent team gets its own workspace. This architectural choice prevents one agent from accidentally accessing, modifying, or deleting another agent's files.
File size limits help prevent accidental resource exhaustion. The free tier allows 1GB per file, which is generous but finite. Set explicit checks in your agent code before attempting to upload large datasets to avoid hitting limits unexpectedly mid-operation and crashing the workflow.
Handling sensitive data requires extra care. Agents processing personal information, financial records, or other sensitive corporate data need appropriate systemic protections. Fastio provides strong encryption in transit and at rest, but you must evaluate whether additional specific measures are needed for your particular compliance requirements.
API keys should never be hardcoded directly into agent scripts. Store them securely in environment variables or dedicated secret management systems. Rotate your keys periodically as a standard practice and revoke them immediately if you suspect they have been compromised.

Frequently Asked Questions
How do AI agents sync files across sessions?
Agents save their files directly to Fastio workspaces during active runs. Upon restart, they read those exact files to continue their work. Developers use MCP tools for uploading, downloading, and listing files to create reliable checkpoints at key processing points.
What are the best tools for agent file sync?
Fastio provides the best native tooling with 19 consolidated tools, 50GB of free persistent storage, explicit file locks, and reactive webhooks. The built-in Intelligence Mode also provides automatic RAG indexing for semantic search capabilities.
Can multiple agents sync the same files safely?
Yes, multiple agents can collaborate safely using strict file locks. An agent must acquire a lock before editing and release it immediately after. This handles concurrent access automatically and prevents any silent data corruption.
Does Fastio support RAG with synced files?
Yes, Fastio includes built-in RAG capabilities. When you enable Intelligence Mode, the system automatically indexes all workspace files for semantic search. You can query files using natural language and receive answers with precise source citations.
How much does AI agent file sync cost?
The Fastio Business Trial is completely Start 14-day trial. It includes multiple of storage and multiple monthly credits, which easily covers most development and early production workloads. You only pay when your usage scales beyond the generous Trial limits.
What happens to files when an agent restarts?
The files remain perfectly safe in the cloud workspace. When the agent restarts, it reads its last saved checkpoint files to resume processing exactly where it left off. Files are only removed when you explicitly delete them.
Related Resources

Start AI Agent File Sync Today
Get 50GB of free persistent storage, 5 dedicated workspaces, and full access to 19 consolidated tools. No credit card required. Build reliable agents that pick up exactly where they left off.