How to Migrate Agent Storage to Fastio API
Migrating agent storage to Fastio involves mapping flat bucket structures into semantic workspaces and replacing raw object SDKs with intelligent Fastio API tool calls. This guide walks through the complete migration process, from assessing your current storage topology to updating agent code to use Fastio MCP tools or REST APIs. You'll learn how to sync existing files, restructure data into workspaces, and use built-in RAG capabilities that eliminate the need for separate vector databases.

Why Migrate Agent Storage to Fastio?
Many AI agent developers start with AWS S3 or similar object storage because it is familiar and readily available. However, raw object storage was designed for generic file hosting, not for the intelligent workflows that modern AI agents require. When you migrate agent storage to Fastio, you gain significant capabilities that would require substantial custom engineering to replicate on S3.
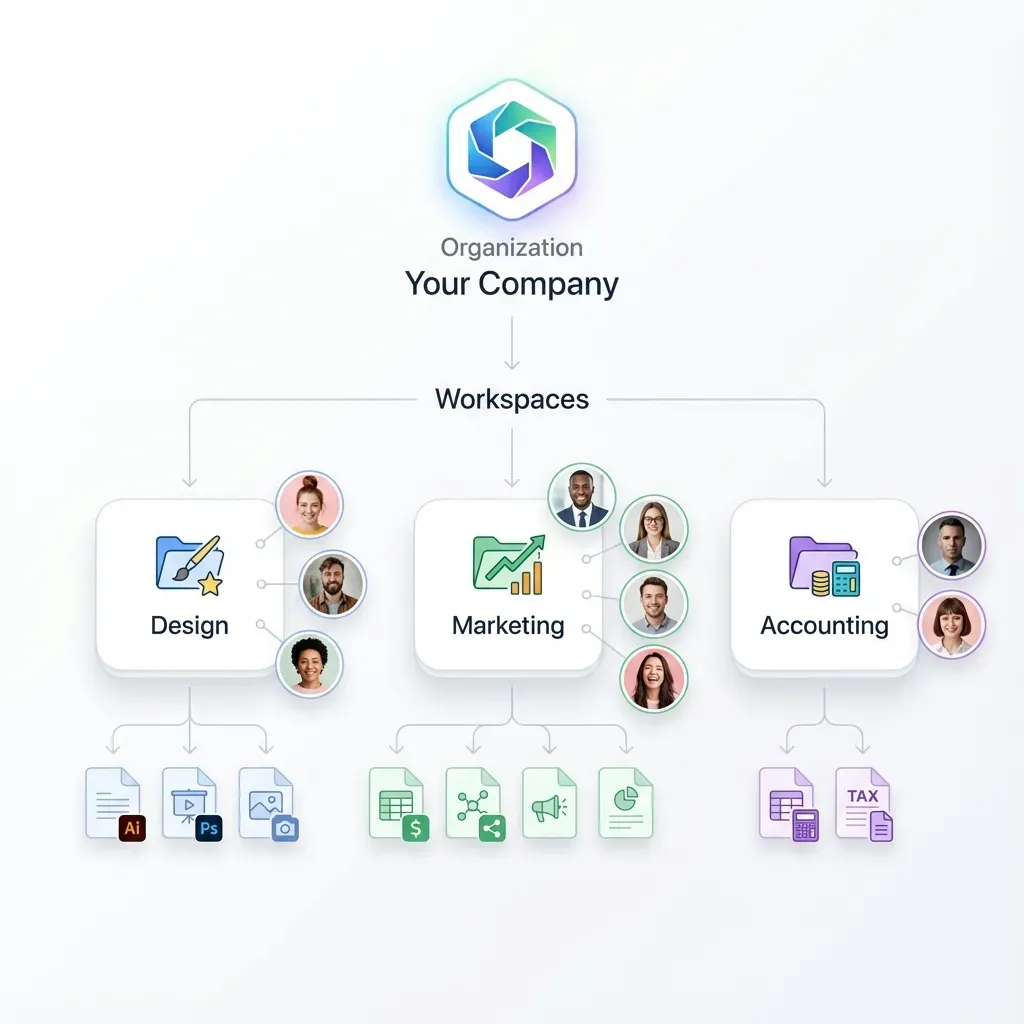
Fastio workspaces provide semantic organization that flat buckets cannot match. Instead of managing complex prefix hierarchies and manually tracking which files belong to which agent runs, workspaces give each agent project its own logical container. Agents can create, organize, and share workspaces just like human team members, using the same tools and interfaces.
The most compelling reason to migrate involves built-in intelligence features. When you enable Intelligence Mode on a Fastio workspace, all uploaded files are automatically indexed for semantic search and RAG queries. This eliminates the need to maintain a separate vector database like Pinecone or Weaviate for your agent's knowledge retrieval. Your agents can query workspace files using natural language and receive cited answers, all without additional infrastructure.
Consider a typical agent that scrapes web pages and stores results in S3. Finding specific information later requires either precise key names or scanning through all stored objects. The same agent on Fastio can ask "What did we find about X topic?" and receive answers with source citations. This capability transforms how agents interact with their stored data.
The Business Trial makes experimentation low-risk. You get multiple of persistent storage, multiple workspaces, and multiple monthly credits without providing credit card information. This is enough to migrate production agents or thoroughly test the migration process before committing.
Helpful references: Fastio Workspaces, Fastio Collaboration, and Fastio AI.

Assessing Your Current Agent Storage Architecture
Before starting the migration, document your current storage setup to understand what needs to move and how to map it to Fastio workspaces. This assessment prevents surprises during the migration process.
Start by identifying all S3 buckets or object storage containers your agents currently use. List each bucket along with the types of files stored, typical file sizes, and access patterns. Note which agents read from and write to each bucket, as this information guides workspace allocation in Fastio.
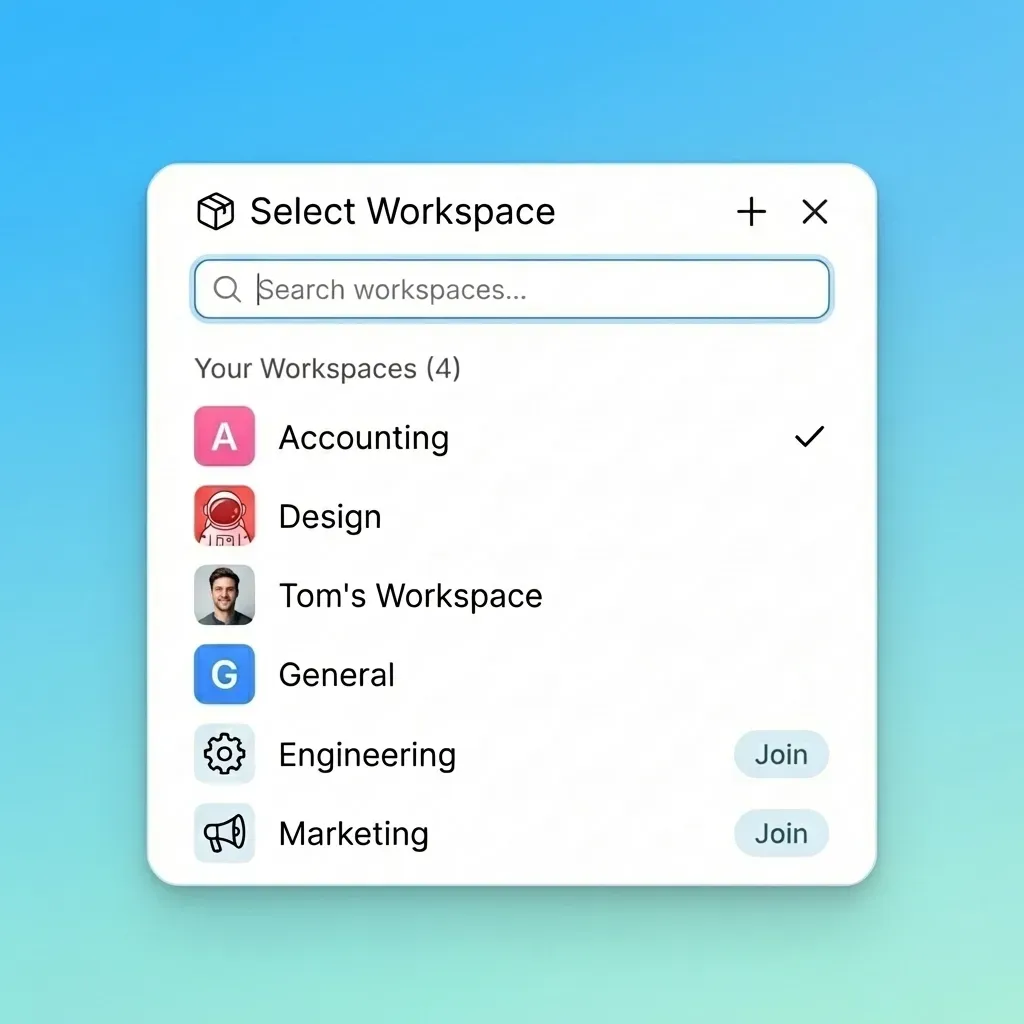
Map your current naming conventions and prefix structures. S3 buckets often use prefixes like agents/{agent_id}/runs/{timestamp}/outputs/ to organize files. Fastio workspaces replace this flat structure with hierarchical organization. Each workspace can contain unlimited folders, and you can create separate workspaces for different agents, projects, or clients.
Count the total storage size across all buckets. The Business Trial supports 50GB, which covers most development and early production workloads. If your data exceeds this, plan which files to migrate first or consider upgrading to a paid plan.
Document your current authentication approach. S3 uses IAM keys and secrets. Fastio uses API tokens with configurable scopes. You will need to generate new credentials and update your agent configuration during the migration.
Review your current vector database usage, if any. Many agents maintain separate Pinecone or Weaviate indexes for RAG functionality. After migrating to Fastio, you can disable these indexes since Intelligence Mode provides equivalent semantic search directly within workspaces.

How to Map Data Structures to Workspaces
The first actual migration step involves planning how your current data maps to Fastio workspace organization. This structural mapping ensures your agents can find files after the migration completes.
Create a workspace for each distinct agent project or data domain. Rather than dumping everything into one workspace, organize by agent function. A research agent gets a research workspace. A data processing agent gets a processing workspace. This separation mirrors how human teams organize their shared drives.
Within each workspace, replicate your prefix hierarchy as folders. If your S3 structure uses agents/scraper/multiple/multiple/results.json, create the equivalent path in Fastio: /agents/scraper/multiple/multiple/results.json. Your agents will find files at the expected locations.
Set up workspace permissions during this phase. Fastio supports granular access controls at the workspace level. Decide whether agents should have full read/write access or more restricted permissions. You can also invite human collaborators to workspaces where agent outputs need human review.
Enable Intelligence Mode on workspaces where you want semantic search and RAG capabilities. The toggle is per-workspace, so enable it selectively based on which workspaces need AI-powered retrieval. Workspaces with Intelligence Mode enabled automatically index uploaded files for semantic queries.
Document your mapping decisions in a migration spreadsheet. Track source bucket, source prefix, destination workspace, destination folder, and any agent code changes required. This documentation guides the actual file sync and code updates.
How to Sync Existing Files to Fastio
With the workspace structure defined, the next step involves moving your existing files from S3 to Fastio. This sync process preserves your data while transitioning to the new storage backend.
Use the Fastio URL Import feature to pull files directly from S3 without downloading locally. This approach is efficient for large datasets because the transfer happens server-to-server. Provide the S3 URL, and Fastio imports the file into the designated workspace.
For bulk migrations, consider writing a script that iterates through your S3 objects and imports them systematically. The script should respect rate limits and handle failures gracefully. If an import fails, log the error and continue with remaining files, then retry failed imports afterward.
Verify file integrity after import. Compare checksums between original S3 objects and imported Fastio files. Any discrepancies indicate transfer errors that require re-importing affected files.
Update your folder organization during this phase. If certain file types belong in specific subfolders, move them now. Fastio supports the same folder operations as traditional file systems, just accessible via API.
Test access patterns after syncing. Run your agent's file listing and reading operations against Fastio to ensure the workspace structure supports expected workflows. Adjust folder organization if agents struggle to locate files.
Consider setting up webhooks during this phase. Webhooks notify your systems when files change in Fastio, enabling reactive agent workflows that respond to new uploads without polling.
Update Agent Code to Use Fastio Tools
The most substantial migration step involves updating your agent code to use Fastio MCP tools or REST APIs instead of S3 SDK calls. This section covers the key changes required.
Choose your integration approach first. The Model Context Protocol (MCP) provides the fast development experience for agents built with Claude, OpenAI Agents SDK, or other MCP-compatible frameworks. The REST API suits agents using custom HTTP clients, LangChain, or frameworks lacking MCP support.
Replace S3 upload calls with Fastio file upload tools. The MCP tool upload_file accepts workspace ID, file path, and file content. For larger files, use chunked upload to handle files up to multiple. The REST API offers equivalent endpoints with standard HTTP methods.
Update file listing operations. Instead of S3 list_objects_v2 calls, use MCP tools to list files within workspaces. The results include file metadata like size, created date, and modification history.
Replace download operations with Fastio file reading tools. The MCP download_file tool retrieves file content directly into your agent's context. No local file handling required.
Implement file locking for concurrent access. If multiple agents modify the same files, acquire locks before writing and release after. This prevents the silent data corruption common in multi-agent systems.
Add webhook handlers if your agents need to react to file changes. When enabled, webhooks POST to your specified URL whenever files are uploaded, modified, or accessed. This enables event-driven architectures without continuous polling.
Test thoroughly after updating code. Run your agents through typical workflows and verify file operations succeed. Check that error handling works correctly when files are missing or permissions are insufficient.

Verify Context and RAG Functionality
After migrating files and updating code, verify that your agents can effectively query and use stored data. This step confirms the migration succeeded and that Fastio intelligence features work as expected.
Test semantic search capabilities. With Intelligence Mode enabled, ask your agent to find files containing specific concepts rather than exact keywords. Verify that results are relevant and that the system provides source citations. This verifies the auto-indexing is working correctly.
Test RAG query workflows. If your agent uses retrieval-augmented generation, replace existing vector database queries with Fastio workspace queries. Compare result quality and citation accuracy. You may find Fastio's built-in RAG produces better results because it operates on complete files rather than chunked embeddings.
Verify webhook functionality if you implemented reactive workflows. Upload a test file and confirm your webhook endpoint receives the notification. Check that the payload includes correct workspace and file information.
Run end-to-end agent tests that exercise the complete storage lifecycle. Agents should create files, read files, search semantically, and handle concurrent access correctly. Any failures indicate areas requiring code adjustments.
Monitor credit usage during testing. The free tier includes included credits monthly, with credits consumed for storage, bandwidth, and AI operations. Track usage through the Fastio dashboard to avoid unexpected limits.
Document any workflow differences discovered during testing. Some S3 patterns may need adjustment for Fastio equivalents. Update agent documentation and runbooks to reflect the new storage backend.
Comparing Fastio to S3 for Agent Storage
Understanding the differences between Fastio and S3 helps set appropriate expectations and ensures you use Fastio's strengths effectively.
S3 provides raw object storage with virtually unlimited capacity and enterprise-grade durability. It integrates deeply with AWS services like Lambda, Glue, and SageMaker. However, S3 provides no built-in intelligence, collaboration features, or agent-specific tooling. Building these capabilities requires significant custom engineering.
Fastio provides intelligent workspaces designed for agent-human collaboration. Built-in RAG, semantic search, and MCP tools reduce the infrastructure your agents need. The collaboration features let humans review and approve agent outputs within the same workspaces where agents work.
The pricing models differ . S3 charges per GB stored and per request, with additional costs for data transfer out. Fastio uses a credit-based system with a generous free tier. For most agent workloads, the free tier's 50GB storage and included credits cover production needs without payment.
Fastio does not replace S3 for all use cases. Large-scale data pipelines processing terabytes may find S3 more cost-effective. However, for agent storage where intelligence and collaboration matter, Fastio provides superior functionality out of the box.
The key advantage is eliminating separate services. RAG, file sharing, collaboration, and storage all work within Fastio. This reduces complexity, lowers costs, and improves agent workflows compared to assembling these capabilities from multiple services.


Give Your AI Agents Persistent Storage
Get generous storage, 5 workspaces, and full MCP tool access. No credit card required. Start your migration today and eliminate the need for separate vector databases. Built for migrating agent storage fast api workflows.
Troubleshooting Migration Issues
Migration projects occasionally encounter problems. Here are solutions for the most common issues developers face when moving agent storage to Fastio.
Files not appearing after import usually indicates incorrect workspace or path specification. Verify the destination workspace ID matches what you created. Check that folder paths use forward slashes and start from the workspace root. The import process may have failed silently if the source URL was incorrect.
Agent authentication failures typically stem from token configuration. Generate fresh API tokens from the Fastio dashboard. Verify the token includes required scopes for the operations your agent performs. Common required scopes include read, write, lock, and workspace management.
Slow file operations may result from large file handling. For files approaching the multiple limit, use chunked upload instead of single requests. Monitor credit usage to ensure you have sufficient bandwidth allocation. Consider distributing large uploads across multiple agent runs using webhooks.
Semantic search returning poor results usually means Intelligence Mode is disabled or files are too new. Enable Intelligence Mode on the workspace and wait for indexing to complete. recent uploads may not yet be indexed. Re-run queries after a few minutes.
Multi-agent lock conflicts occur when agents attempt simultaneous writes. Implement exponential backoff retry logic in your agent code. If a lock is held, wait and retry with increasing delays. Consider whether your workflow can be restructured to reduce concurrent access to the same files.
Credit exhaustion stops operations unexpectedly. Monitor usage through the dashboard and set up alerts for low credit balances. Plan upgrades before hitting limits if your usage approaches free tier thresholds.
Frequently Asked Questions
How do I migrate data to Fastio?
Migrate data to Fastio by creating workspaces matching your current bucket structure, then using URL Import to pull files from S3 directly without downloading locally. Sync files in batches, update agent code to use MCP tools or REST API, and verify Intelligence Mode indexing for semantic search capabilities.
What is the best way to move AI agent storage?
The best approach involves mapping current bucket prefixes to Fastio workspace folders, using server-side import to move files, updating agent code to use Fastio tools instead of S3 SDK, and testing thoroughly to verify workflows. The free tier provides 50GB and included credits for testing the migration.
Can Fastio replace my vector database for agent RAG?
Yes, Fastio Intelligence Mode eliminates the need for separate vector databases. When enabled, workspaces automatically index uploaded files for semantic search and RAG queries. Agents can ask natural language questions and receive cited answers directly from workspace files without managing Pinecone or similar services.
How much does it cost to migrate agent storage?
The Fastio Business Trial is free. It includes multiple storage, multiple workspaces, and multiple monthly credits. This covers most agent storage needs without payment. Usage beyond the free tier uses the credit-based pricing system.
Do I need to rewrite all my agent code to use Fastio?
You need to update file operation code to use Fastio MCP tools or REST API instead of S3 calls. The scope depends on how heavily your agents use storage. Simple replacements for upload, download, list, and delete operations typically take a few hours. Complex S3-specific features may require more substantial changes.
Related Resources

Give Your AI Agents Persistent Storage
Get generous storage, 5 workspaces, and full MCP tool access. No credit card required. Start your migration today and eliminate the need for separate vector databases. Built for migrating agent storage fast api workflows.