How to Coordinate AI Agents with Multi-Agent Orchestration Patterns
Multi-agent orchestration patterns define how AI agents work together to complete tasks. This guide covers the four primary patterns (supervisor, pipeline, swarm, and hierarchical), explains when to use each, and shows how shared storage solves the coordination challenges that trip up most multi-agent systems.

What Are Multi-Agent Orchestration Patterns?
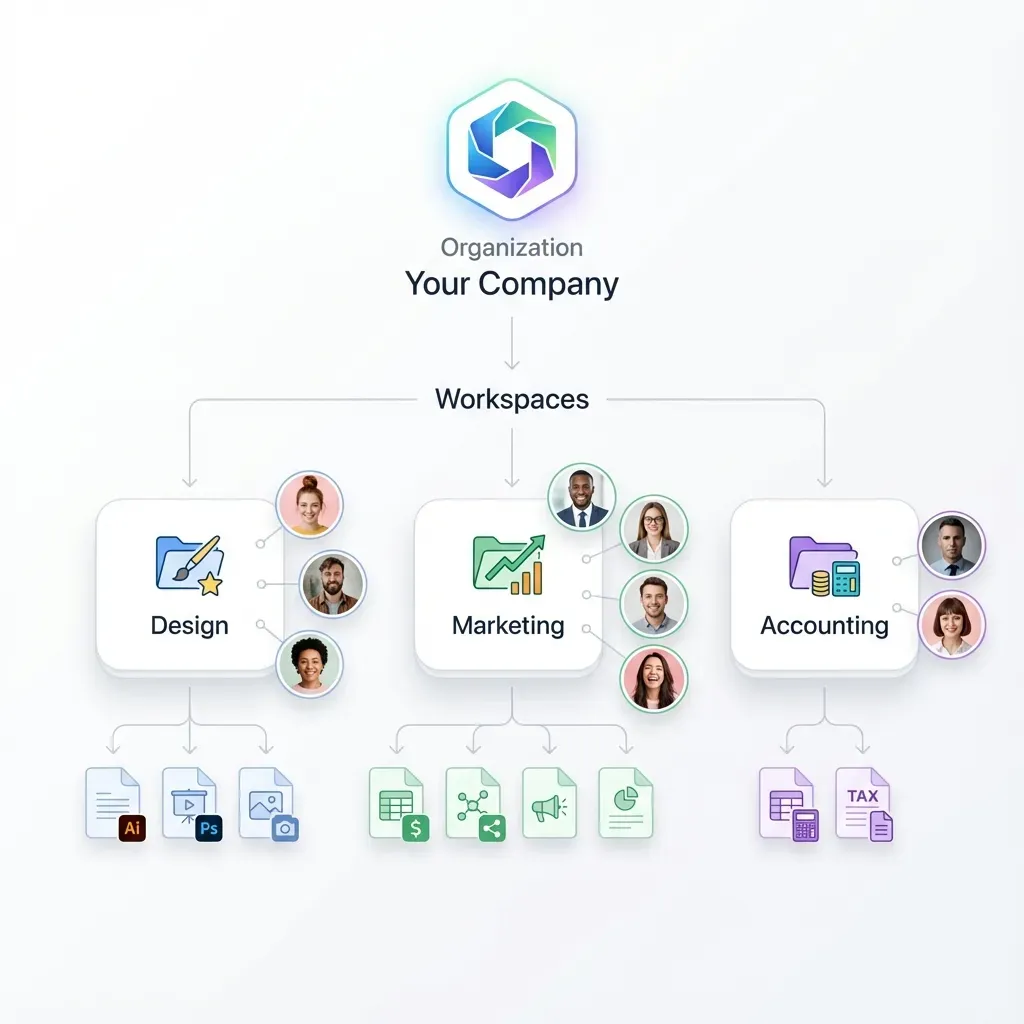
Multi-agent orchestration patterns are architectural approaches for coordinating multiple AI agents to accomplish complex tasks. Rather than relying on a single all-purpose agent, these patterns distribute work across specialized agents that communicate, share state, and hand off tasks in defined ways. The four foundational patterns are:
- Supervisor pattern: A central coordinator assigns tasks and aggregates results
- Pipeline pattern: Agents process work in sequence, each refining the previous output
- Swarm pattern: Autonomous agents work in parallel with minimal coordination
- Hierarchical pattern: Multi-level structure with managers directing specialists
These patterns address the core challenge of multi-agent systems: how do agents share context, avoid conflicts, and produce coherent outputs? The answer varies by use case, but all patterns require some mechanism for shared state.
Helpful references: Fast.io Workspaces, Fast.io Collaboration, and Fast.io AI.
The Supervisor Pattern
The supervisor pattern uses a single orchestrator agent that delegates tasks to worker agents and synthesizes their outputs. Think of it as a project manager directing a team.
How it works:
- User request arrives at the supervisor agent
- Supervisor breaks the task into subtasks
- Supervisor assigns subtasks to appropriate specialist agents
- Worker agents complete tasks and return results
- Supervisor aggregates results and responds to user
When to use it:
- Tasks requiring multiple specialized skills (research, writing, coding)
- Situations needing quality control over agent outputs
- Workflows where a human-like decision point improves results
Trade-offs:
The supervisor becomes a bottleneck. Every interaction routes through it, adding latency. The supervisor also needs enough context to make good delegation decisions, which can strain token limits in complex workflows.
Example implementation:
class SupervisorAgent:
def __init__(self, workers: list[Agent]):
self.workers = {w.name: w for w in workers}
self.storage = FastIOWorkspace("supervisor-context")
def process(self, task: str) -> str:
### Break task into subtasks
plan = self.plan_subtasks(task)
### Delegate to workers
results = []
for subtask in plan:
worker = self.workers[subtask.agent_name]
result = worker.execute(subtask.instructions)
### Store intermediate results for context
self.storage.save(f"{subtask.id}.json", result)
results.append(result)
### Synthesize final response
return self.synthesize(results)
The supervisor pattern dominates enterprise deployments because it matches how human teams already work, as supervisor-based architectures drive most production implementations.

The Pipeline Pattern
The pipeline pattern chains agents in sequence, where each agent processes the output of the previous one. This mirrors assembly lines or content production workflows.
How it works:
- Input enters the first agent in the pipeline
- Each agent transforms, enriches, or refines the data
- Output flows to the next agent automatically
- Final agent produces the completed result
When to use it:
- Content production (research → write → edit → format)
- Data processing with clear transformation stages
- Quality control workflows where each stage adds value
- Tasks with natural sequential dependencies
Pipeline patterns commonly appear in production multi-agent systems because they match how work naturally flows. The pattern works best when each stage has a clear input/output contract.
Example: Content Pipeline
Researcher → Writer → Editor → Humanizer
↓ ↓ ↓ ↓
Sources Draft Polished Final
Trade-offs:
Pipeline failures cascade. If one stage produces poor output, the next cannot recover. You need checkpoints and rollback mechanisms. Latency adds up since each stage must complete before the next begins.
Storage requirement:
Pipelines need persistent storage between stages. Each agent must read the previous stage's output and write its own. Without shared storage, you pass massive payloads between agents, hitting context limits and losing intermediate work if any stage fails. ```python class PipelineStage: def init(self, workspace: str): self.storage = FastIOWorkspace(workspace)
def execute(self, input_key: str, output_key: str): ### Read previous stage output input_data = self.storage.read(input_key)
Process
result = self.process(input_data)
Write for next stage
self.storage.save(output_key, result)
return output_key
The Swarm Pattern
The swarm pattern deploys multiple agents working in parallel on related tasks, with minimal central coordination. Agents operate autonomously and may compete or collaborate.
How it works:
- Multiple agents receive the same or related tasks
- Agents work independently and simultaneously
- Results are aggregated, voted on, or merged
- Best output wins or outputs combine
When to use it:
- Tasks benefiting from diverse approaches (brainstorming, exploration)
- Fault tolerance requirements (if one agent fails, others continue)
- Speed-critical workloads (parallel execution beats sequential)
- Research and analysis with multiple valid perspectives
Trade-offs:
Running five agents costs five times the compute of one agent. Coordination overhead shows up when combining outputs. You may get contradictory results that need reconciliation.
Conflict resolution:
Swarms must handle agents modifying the same resources. Options include:
- Voting: Majority result wins
- Scoring: Quality metric determines winner
- Merge: Combine non-conflicting elements
- Human review: Flag conflicts for manual resolution
Example: Research Swarm
async def research_swarm(query: str, num_agents: int = 3):
workspace = FastIOWorkspace("research-swarm")
### Launch agents in parallel
tasks = [
research_agent(query, f"agent-{i}", workspace)
for i in range(num_agents)
]
results = await asyncio.gather(*tasks)
### Each agent saved findings to shared storage
all_findings = workspace.list_files("findings/")
### Synthesize diverse perspectives
return synthesize_findings(all_findings)


Give Your AI Agents Persistent Storage
Fast.io gives AI agents their own workspaces, file locks for concurrent access, and webhooks for event-driven patterns. 50GB free, no credit card required. 251 MCP tools for seamless integration.
The Hierarchical Pattern
The hierarchical pattern creates multiple levels of agent management, with executive agents directing manager agents who direct worker agents. This scales the supervisor pattern for complex organizations.
How it works:
- Executive agent receives high-level objectives
- Executive breaks objectives into projects for manager agents
- Manager agents decompose projects into tasks for workers
- Workers execute and report up the chain
- Results aggregate upward through the hierarchy
When to use it:
- Large-scale systems with many specialized agents
- Complex domains requiring different expertise levels
- Organizations wanting AI to mirror their structure
- Workflows requiring approval chains or escalation
Example structure:
CEO Agent
├── Engineering Manager Agent
│ ├── Backend Developer Agent
│ ├── Frontend Developer Agent
│ └── QA Agent
└── Content Manager Agent
├── Writer Agent
├── Editor Agent
└── SEO Agent
Trade-offs:
Hierarchies add latency at each level. Communication overhead grows with depth. You need clear delegation rules to prevent agents from escalating everything upward. The pattern can get rigid and handle novel situations poorly.
State management challenge:
Hierarchical systems generate state at every level. Each manager needs visibility into their workers' progress. Each executive needs summaries from managers. Without persistent shared storage, this context constantly re-transmits through the hierarchy, wasting tokens and risking inconsistency. Proper orchestration reduces agent conflicts by 80% when using hierarchical patterns with shared state management.
Choosing the Right Pattern
No single pattern fits all use cases. Here's a decision framework:
Pattern combinations:
Real systems often combine patterns. A hierarchical structure might use pipelines within each team. A supervisor might spawn swarms for parallel exploration. The key is matching pattern to task characteristics:
- Sequential dependencies → Pipeline
- Need for oversight → Supervisor or Hierarchical
- Parallelizable work → Swarm
- Scale requirements → Hierarchical
Questions to ask:
- Do tasks depend on each other's outputs? (Yes → Pipeline)
- Do I need quality control checkpoints? (Yes → Supervisor)
- Can work happen in parallel? (Yes → Swarm)
- Am I coordinating large teams of agents? (Yes → Hierarchical)
The Shared Storage Problem
Every orchestration pattern needs one thing: persistent, shared storage for coordination. Without it, you face:
- Context loss: Intermediate results disappear between agent calls
- Payload bloat: Passing full context through every handoff
- Race conditions: Agents overwriting each other's work
- Recovery failures: No checkpoint to resume from after crashes
Most documentation describes patterns without showing how agents actually share files and state. This gap is why many multi-agent POCs fail when moving to production.
What agents need from storage:
- Persistent workspaces: Files survive agent restarts
- Concurrent access: Multiple agents read/write safely
- Permissions: Control which agents access which files
- Versioning: Track changes and enable rollback
- API access: Programmatic operations, not manual uploads
The Fast.io approach:
AI agents register for storage accounts like human users. Each agent gets:
- Personal workspace for private working files
- Shared workspaces for team coordination
- Full API access for file operations
- MCP integration for Claude and compatible agents
- Free tier with 5,000 credits monthly
from fastio import Agent
### Agent authenticates like a user
agent = Agent.authenticate(api_key="...")
### Create workspace for this pipeline run
workspace = agent.create_workspace("content-pipeline-2024-02")
### Upload files, share with other agents
workspace.upload("research.json", research_data)
workspace.invite("writer-agent@fastio.ai", role="editor")
The MCP server at mcp.fast.io provides native integration for Claude-based agents, eliminating boilerplate for common file operations.
Implementation Checklist
When building multi-agent systems, address these requirements:
Architecture decisions
- Choose primary orchestration pattern based on workflow shape
- Define agent boundaries and responsibilities
- Establish handoff protocols between agents
- Plan for hybrid patterns if needed
State management
- Set up persistent storage accessible to all agents
- Define file naming conventions for clarity
- Implement conflict resolution for concurrent writes
- Create rollback/recovery procedures
Agent configuration - [ ] Provision storage accounts for each agent
- Configure workspace permissions appropriately
- Set up API keys and authentication
- Test agent-to-agent file sharing
Monitoring
- Log agent activities and handoffs
- Track pipeline stage completion times
- Monitor storage usage and quotas
- Alert on failures and retries
Testing
- Unit test individual agents
- Integration test full pipelines
- Load test concurrent agent operations
- Chaos test recovery procedures
Frequently Asked Questions
What are multi-agent patterns?
Multi-agent patterns are architectural approaches for coordinating multiple AI agents. The four core patterns are supervisor (central coordinator), pipeline (sequential processing), swarm (parallel autonomous agents), and hierarchical (multi-level management). Each pattern addresses different coordination needs and trade-offs around latency, control, and scalability.
How do agents coordinate?
Agents coordinate through shared state and defined communication protocols. The most reliable approach uses persistent shared storage where agents read and write files. This avoids the context loss and payload bloat of passing everything through API calls. Agents also coordinate through direct handoffs (pipeline), central orchestration (supervisor), or autonomously with result aggregation (swarm).
What is the best multi-agent architecture?
It depends on your workflow. Pipeline works best for sequential processes like content production. Supervisor works for general-purpose coordination with quality control. Swarm handles parallel exploration and fault tolerance well. Hierarchical works for large-scale systems with many agents. Most production systems combine patterns.
How do I prevent agents from conflicting with each other?
Prevent conflicts through clear workspace isolation, defined file ownership, and explicit handoff protocols. Use storage systems that handle concurrent access safely. Assign each agent specific directories or file prefixes. For swarms, implement voting or merge strategies for reconciling different outputs. Proper orchestration with shared storage reduces agent conflicts by 80%.
Can different orchestration patterns be combined?
Yes, hybrid architectures are common in production. A hierarchical system might use pipelines within each team. A supervisor might spawn swarms for parallel research. Match each part of your workflow to the right pattern, using persistent storage as the coordination backbone across all patterns.
Related Resources

Give Your AI Agents Persistent Storage
Fast.io gives AI agents their own workspaces, file locks for concurrent access, and webhooks for event-driven patterns. 50GB free, no credit card required. 251 MCP tools for seamless integration.