How to Implement AI Agent Production Logging
Logging for AI agents requires capturing traces, reasoning chains, decisions, API calls, and errors for effective debugging.
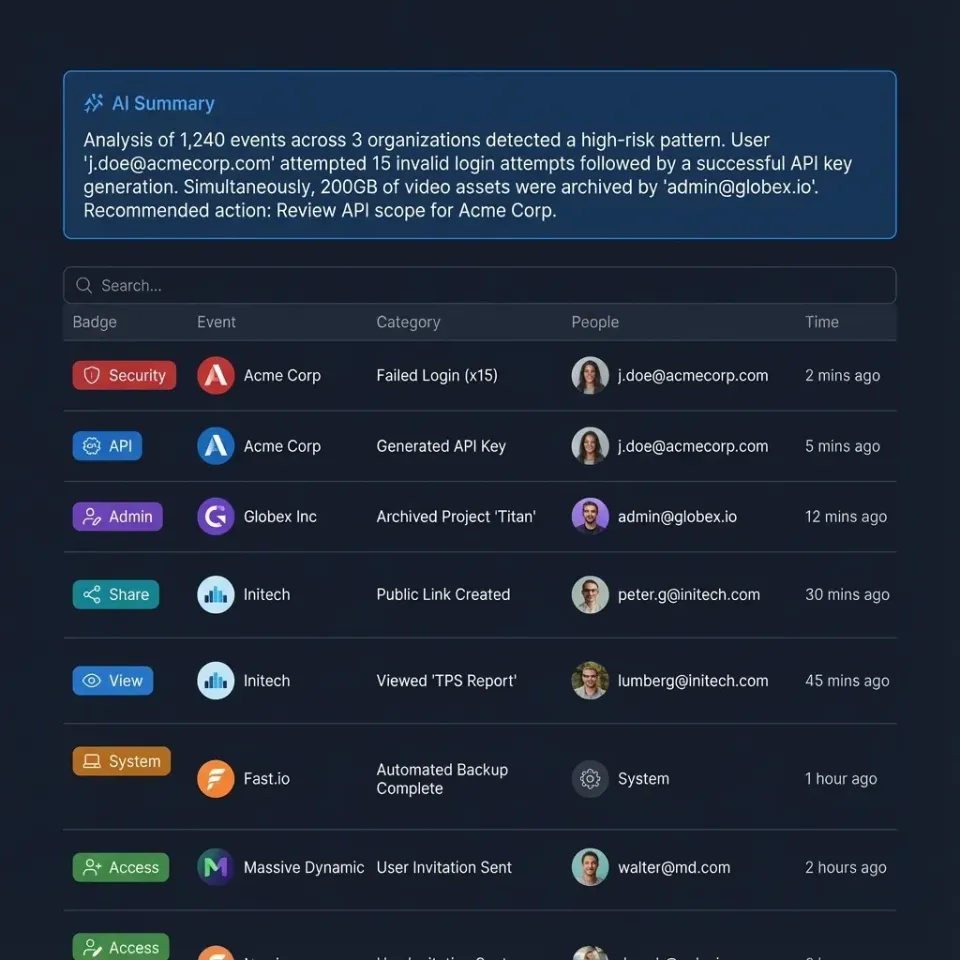
Why Standard Application Logging Fails for AI Agents
Standard software logging is deterministic: you log a request, a database query, and a response. If an error occurs, the stack trace usually points directly to the problem code.
AI agents are non-deterministic, which breaks this model.
Agents "think" before they act. They make decisions based on probabilistic models, call tools in varying sequences, and handle unstructured natural language inputs. A standard error log might tell you that an agent failed to retrieve data, but it won't tell you why it decided to query the wrong database or formulated a bad SQL query.
The Complexity of Agent Workflows Consider a customer support agent. In one session, it might answer directly. In another identical session, it might call a "refund_tool" first, then an "email_tool". If it gets stuck in a loop calling the same tool repeatedly, a standard access log will just show 50 HTTP 200 OK responses. It won't reveal that the agent is hallucinating parameters and failing to make progress.
A 2025 survey by the AI Infrastructure Alliance highlighted this gap, showing that 85% of agent debugging time goes to manually piecing together scattered logs to reconstruct the agent's "thought process." To fix bugs in production, you need to capture the chain of thought, the prompt context, and the tool outputs that led to a specific state.
Helpful references: Fastio Workspaces, Fastio Collaboration, and Fastio AI.
What to check before scaling ai agent production logging
To debug and monitor agents, your logging strategy must capture six distinct dimensions of data. Missing any one of these leaves you with a blind spot during a production incident.
1. Interaction Traces (The "Conversation")
This is the highest level of logging: what did the user say, and what did the agent reply? This includes the raw prompt and the final completion. It serves as the "ground truth" of the user experience.
- What to log: Timestamp, User ID, Session ID, Input Text, Output Text.
- Why it matters: Essential for analyzing user intent and overall satisfaction.
2. Reasoning Chains (The "Thoughts")
If your agent uses frameworks like ReAct, LangChain, or AutoGen, it generates internal reasoning steps ("thoughts") before taking action. These thoughts explain hallucinations or logic errors.
- What to log: The
thoughtorreasoningblock generated by the LLM. - Why it matters: Reveals why the agent made a decision. Did it misunderstand the tool description? Did it ignore a constraint?
3. Tool Execution Traces (The "Actions")
Agents interact with the outside world via tools. You must log every attempt to call a tool, the arguments passed, and the raw output returned.
- What to log: Tool Name, Arguments (JSON), Execution Time (ms), Status (Success/Fail), Raw Output.
- Why it matters: Most agent failures happen here. Perhaps the agent hallucinated a parameter that doesn't exist, or the tool returned an error message the agent couldn't parse.
4. State Snapshots (The "Context")
Agents maintain state: memory of past turns, summarized context, or loaded documents. You need snapshots of this state to reproduce bugs.
- What to log: The contents of the context window or "memory" at key checkpoints.
- Why it matters: Allows you to "replay" the agent's session from a specific point to reproduce erratic behavior.
5. Cost and Latency Metrics (The "Economics")
LLMs charge by the token. A runaway loop can cost hundreds of dollars in minutes.
- What to log: Input Tokens, Output Tokens, Model Name, Total Latency, Time-to-First-Token (TTFT).
- Why it matters: Key for unit economics. You need to know the "Cost Per Resolution" for your agent, not just the monthly bill.
6. Structured Error Context (The "Crash")
When things break, you need more than a stack trace. You need the specific input that caused the crash.
- What to log: Error Message, Stack Trace, Last Known State, Retry Count.
- Why it matters: Helps you fix fatal errors quickly.

Designing a JSON Log Schema for Agents
Unstructured text logs are useless at scale. You cannot query "Show me all sessions where the refund tool failed" if your logs are just lines of text. Production agent logs must be structured JSON.
Here is a recommended JSON schema structure for a single agent action event. This structure lets you index and search across all dimensions of the agent's behavior.
{
"timestamp": "2026-02-13T14:30:00Z",
"level": "INFO",
"trace_id": "trc_8829304-ab",
"span_id": "spn_9920111-cd",
"parent_span_id": "spn_5544332-ef",
"agent_id": "customer-support-bot-v2",
"event_type": "TOOL_EXECUTION",
"data": {
"tool_name": "check_order_status",
"input_arguments": {
"order_id": "ORD-12345"
},
"output_result": {
"status": "shipped",
"tracking": "UPS123456"
},
"duration_ms": 450,
"model": "claude-3-5-sonnet",
"token_usage": {
"prompt": 150,
"completion": 45
}
},
"metadata": {
"user_id": "usr_555",
"session_id": "ses_777",
"environment": "production"
}
}
Using Correlation IDs (trace_id)
Notice the trace_id. This is the most important field. It must be generated when the user request first hits your system and passed down to every sub-agent, tool, and API call.
By filtering on a trace_id, you can reconstruct the entire timeline of a request across distributed systems. If your agent delegates a task to a sub-agent, that sub-agent logs its own activities using the same trace_id (but different span_id), preserving the causal link.
Persistent Storage Strategies for Agent Logs
AI agents create much more log data than traditional apps because they log full text prompts and completions. A single complex task might generate megabytes of text data.
The Problem with Ephemeral Storage
Running agents in containers (like Docker or Kubernetes pods) and logging to stdout or local files is risky.
- Container Restarts: If the agent crashes or the container restarts, local logs are lost forever.
- Context Loss: You lose the "memory" of what the agent was doing right before the crash.
- No Search: Grepping through text files on a server is slow and inefficient.
Use Dedicated Cloud Storage You need a persistent, append-only storage solution that lives outside your compute environment. This ensures that even if your agent infrastructure vanishes, the forensic data remains.
Fastio for Agent Logging Fastio works well for agent logs. Because it functions as a global drive, your agents can append logs directly to cloud files as if they were local.
- Append-Only Safety: Agents can write data without the risk of overwriting or deleting past history.
- Easy Integration: Using the Fastio MCP server, you can add logging capabilities to any agent with a single tool definition.
- Intelligence Mode: Once logs are stored in Fastio, you can use built-in AI to query them (e.g., "Find all logs where the 'refund' tool failed yesterday").


Give Your AI Agents Persistent Storage
Get 50GB of persistent storage to keep your agent traces, logs, and artifacts safe, searchable, and accessible via API.
Implementing Logging with Fastio MCP
Here is how to set up production logging using the Fastio Model Context Protocol (MCP) server. This approach works with any agent framework that supports tool use.
Step 1: Connect the MCP Server
Give your agent access to the Fastio MCP server. This provides the append_file tool.
Step 2: Define the Logging Helper Create a helper function in your agent's code to format and send logs.
import json
import datetime
import uuid
### Global trace ID for the current session
CURRENT_TRACE_ID = str(uuid.uuid4())
async def log_agent_event(agent, event_type, data):
"""
Logs a structured event to Fastio storage.
"""
log_entry = {
"timestamp": datetime.datetime.utcnow().isoformat(),
"trace_id": CURRENT_TRACE_ID,
"agent_name": agent.name,
"event_type": event_type, # e.g., "THOUGHT", "TOOL_CALL", "ERROR"
"data": data
}
### Convert to JSON string (one line per entry for JSONL format)
log_line = json.dumps(log_entry) + "
"
### Define the daily log file path
today = datetime.datetime.now().strftime("%Y-%m-%d")
log_file_path = f"logs/production/{today}-agent-traces.jsonl"
### Use the MCP tool to append safely
await agent.use_tool(
"fastio_append_file",
path=log_file_path,
content=log_line
)
Step 3: Instrument Your Agent Loop Call this logger at key points in your agent's execution loop.
### Example inside an agent loop
async def run_step(user_input):
### Log the input
await log_agent_event(agent, "INPUT", {"text": user_input})
### ... agent thinking ...
thought = await llm.generate_thought(user_input)
await log_agent_event(agent, "REASONING", {"thought": thought})
### ... tool execution ...
result = await perform_tool(thought.tool, thought.args)
await log_agent_event(agent, "TOOL_RESULT", {
"tool": thought.tool,
"args": thought.args,
"output": result
})
This setup ensures that every critical step is saved immediately to persistent storage. Even if the process crashes on the next line, your logs are safe in Fastio.
Security, Compliance, and PII Redaction
Logging detailed agent interactions creates security risks. Agents often process sensitive user data, and logging raw prompts can accidentally save Personally Identifiable Information (PII) or secrets (like API keys) to disk.
Automated Redaction Before any log entry is written to storage, it should pass through a "sanitizer" function.
- Regex Patterns: Scan for and mask patterns that look like emails, credit card numbers, or SSNs.
- Secret Detection: Ensure no string matching known environment variables or API keys is ever logged.
- Allow-listing: Prefer logging only known-safe fields rather than trying to blocklist everything.
Retention Policies Compliance frameworks like privacy requirements require you to delete user data upon request and limit retention periods.
- Short-term (30 days): Keep detailed, full-text debug logs (JSONL) to fix active bugs.
- Long-term (1 year): Keep aggregated metrics (cost, success rate) but delete the raw conversation text.
- Deletion Requests: Because you are using structured logging with
user_id, you can easily script a process to find and purge all records for a specific user who exercises their right to be forgotten.
Analyzing Logs for Continuous Improvement
Collecting logs is only the first step. The value comes from analyzing them to improve your agent's performance.
Detecting "Drift" Agents can degrade over time as models change or user behaviors shift. Monitor your logs for:
- Tool Error Rate: A spike in failures for a specific tool might indicate an API change or a hallucinated parameter.
- Loop Detection: Identification of sessions with >10 turns, which often indicates the agent is stuck.
- Sentiment Drop: Tracking user sentiment in the final response can alert you to quality issues.
Cost Optimization Analyze your token usage logs to identify expensive queries. You might find that 80% of your cost comes from a "summarize" step that could be handled by a smaller, cheaper model.
Frequently Asked Questions
What is the difference between tracing and logging for agents?
Logging typically records discrete events (errors, status updates). Tracing records the continuous journey of a request through the system, linking the user prompt, agent thoughts, tool calls, and final response into a single connected view.
How can I calculate the cost of my AI agent per session?
You must log the input and output token counts for every LLM call, along with the model name. By summing these tokens and applying the pricing for each model (e.g., $3/1M tokens), you can calculate the exact cost for each unique `session_id`.
Is it safe to log full LLM prompts and responses?
It is useful for debugging but carries security risks. You should log them in development. In production, you must implement PII scrubbing (redaction) to mask emails, phone numbers, and secrets before writing to logs.
What is a 'trace ID' and why do I need it?
A trace ID is a unique string generated at the start of a request. It is passed to every component (sub-agents, tools). It allows you to filter your logs to see everything related to that one specific user request, ignoring all other noise.
How do I prevent logs from filling up my storage?
Use log rotation and retention policies. For example, compress logs older than 7 days and delete logs older than 30 days. Fastio makes this easy by allowing you to manage files programmatically or set up lifecycle rules.
Can I use standard APM tools like Datadog for agent logs?
Yes, but they can be expensive for the volume of text data agents generate. Many teams use APM for metrics (latency, error rates) but use cheaper object storage (like Fastio) for the detailed text traces and reasoning logs.
Related Resources

Give Your AI Agents Persistent Storage
Get 50GB of persistent storage to keep your agent traces, logs, and artifacts safe, searchable, and accessible via API.